
搜索到
40
篇与
的结果
-
code——虚拟环境 写代码第一步 环境刚开始接触各种语言的时候c++ c python的时候或者是直接复现一个简单的项目最头疼的莫过于配置环境 很多代码都是因为环境冲突 环境互相依赖冲突导致跑不起来这时候就会了解到虚拟环境会有各种各样的教程告诉你如何配置虚拟环境巴拉巴拉的但我还是经历了很长时间才真正的理解我刚接触的时候觉得真的好麻烦啊 ::(泪) 为什么不能直接在我的电脑上都能跑通 我还要一遍一遍的配置各种各样的虚拟环境{dotted startColor="#ff6c6c" endColor="#1989fa"/}现在我的理解就是不同的项目依赖的东西就是不同的圈子项目A可能是植物类的 项目B可能是动物类他们直接会有交集 但有些东西又是不一样的 比如植物可以光合作用 动物可以随意运动等等我们不可能做到一个环境统筹所有内容 所以方便起见有了虚拟环境根据管理内容的不同 就有了主要的三种环境虚拟环境 (venv)Conda 环境Docker工具一句话定位隔离对象venvPython 项目的轻量级虚拟环境仅 Python 解释器 + 第三方包conda跨语言的包管理与环境工具Python 解释器 + 第三方包 + 非 Python 依赖(如 CUDA、OpenSSL)Docker操作系统级容器整个文件系统、网络、进程、用户空间{dotted startColor="#ff6c6c" endColor="#1989fa"/}对比维度venvcondaDocker所属生态Python 内置(3.3+)Anaconda / MinicondaDocker Inc.(容器生态)隔离级别进程级(环境变量)进程级(环境变量)操作系统级(namespace + cgroups)隔离对象Python 解释器 + 第三方包Python + 第三方包 + 非 Python 依赖(如 CUDA)整个文件系统、网络、进程、用户空间能否管理 Python 版本❌ 不能(用宿主机 Python)✅ 能(python=3.10)✅ 能(通过不同基础镜像)能否管理非 Python 依赖❌ 不能✅ 能(conda 包可含二进制)✅ 能(任意系统库,如 libssl、ffmpeg)跨平台一致性⚠️ 弱(依赖宿主机 OS)⚠️ 中等(与 OS 绑定,但 conda 预编译)✅ 强(镜像包含完整 OS,行为一致)启动速度极快(毫秒级)快(毫秒级)中等(秒级,需启动容器进程)磁盘占用极小(几 MB,仅存包列表)中等(每环境几百 MB)较大(镜像几百 MB 到几 GB)打包与分发requirements.txtenvironment.ymlDockerfile → 镜像仓库适用场景简单 Python 项目,仅需隔离包版本数据科学、机器学习(需复杂二进制依赖)微服务部署、统一开发/生产环境、系统级隔离生产环境推荐度低中(镜像较大)高(标准部署方式)典型命令python -m venv envconda create -n env python=3.10docker build -t myapp .激活方式source env/bin/activateconda activate envdocker run -it myapp那么就很好理解了 这个venv就是可以把不同python包改善一下版本 conda就是可以把python版本都改了 docker就是可以把你操作系统给改了docker快速安装{dotted startColor="#ff6c6c" endColor="#1989fa"/}通过 Ubuntu 官方仓库安装 (docker.io)这是最简单的方法,但软件版本可能不是最新的。# 1. 更新软件包列表 sudo apt update # 2. 直接通过 apt 安装 docker.io 包 sudo apt install docker.io🧑💻 安装后配置(重要)避免重复输入sudo:默认情况下,运行 Docker 命令需要 sudo 权限。将你的用户添加到 docker 用户组后,重新登录,之后就可以直接使用 docker 命令了。sudo usermod -aG docker $USER⚠️ 安全提示:docker 组的权限等同于 root 用户,请谨慎添加。验证安装是否成功:运行一个简单的测试镜像来验证。docker run hello-world如果安装成功,你会看到一条欢迎消息,说明 Docker 引擎正在运行。{dotted startColor="#ff6c6c" endColor="#1989fa"/}Windows 系统 Docker 安装在Windows上,Docker Desktop是官方推荐的安装方式。建议优先选择使用WSL 2作为后端,其性能更好、资源占用更低。第一步:启用WSL 2功能以管理员身份打开 PowerShell,执行以下命令即可自动安装WSL 2并设置为默认版本:wsl --install如果你的系统不支持此命令,可以手动在“控制面板” -> “程序” -> “启用或关闭 Windows 功能”中,勾选“适用于Linux的Windows子系统”和“虚拟机平台”,然后重启电脑。第二步:下载并安装Docker Desktop下载:访问 Docker 官网下载页面,下载适用于 Windows 的安装包。安装:运行下载的 Docker Desktop Installer.exe,建议在安装过程中勾选 "Use WSL 2 instead of Hyper-V"(使用 WSL 2 代替 Hyper-V)选项。第三步:启动与验证安装完成后,从开始菜单启动 Docker Desktop。Docker 图标会在系统托盘中显示,等待其状态变为 "Docker Desktop is running"。打开 PowerShell 或 命令提示符,输入以下命令验证:docker --version如果输出版本号信息,就说明安装成功了。
-
 Claude code 2026.3.31 文章by程序员鱼皮 文章内容来自程序员鱼皮文章链接 https://www.codefather.cn/post/2039551862717313025堪称全球最强的 AI 编程工具 Claude Code 的 50 多万行源码泄露了!一家以 AI 安全著称的公司,自己却在代码发布环节翻了车。到底是怎么泄露的Claude Code 是通过 npm 发布的,你可以把 npm 理解为程序员的「应用商店」,开发者把写好的工具打包上传到这里,别人一行命令就能安装。正常情况下,代码上线之前会经过「压缩混淆」处理,变成一坨人类看不懂的东西。在开发的时候,为了方便定位 Bug,代码打包工具会自动生成一个叫 Source Map 的文件,它相当于一张「翻译对照表」,能把加密后的代码还原成原始版本。但是这个文件只能在开发环境用,上线时必须删掉!结果 Anthropic 的工程师在发布 Claude Code 2.1.88 版本的时候,打包工具 Bun 默认生成了 Source Map 文件,而他们忘了在发布配置里把 .map 文件排除掉。于是一个 59.8 MB 的 cli.js.map 文件就这么被直接发到了公开的 npm 仓库。这个 map 文件本质上是一个 JSON,里面有两个关键数组,sources 存着所有文件的路径,sourcesContent 存着每个文件的完整源码,两者一一对应。只要写个脚本解析一下这个 JSON,按路径把内容写出来,所有源码就原样还原了。而且据说 map 文件里甚至还引用了一个 Cloudflare R2 存储桶的公开地址,点进去直接就能下载打包好的完整源码目录,连脚本都不用写。安全研究员 Chaofan Shou 最先发现了这个问题并发到了 X 上:然后几个小时之内 GitHub 上就冒出了好几个镜像仓库,源码传遍了整个互联网,其中有个仓库不到 1 天就快 10w Star 了(而且仓库里早就没有 Claude Code 源码了)……更搞笑的是,去年 2 月 Claude Code 刚发布的时候就出过一模一样的事故,同样的错误犯了两次!怕不是 Claude Code 团队的开发者 Vibe Coding 上瘾,连基本操作都忘了?源码里都有什么这次泄露的是 Claude Code 客户端的源码,包括 1906 个 TypeScript 源文件、大约 51.2 万行代码。涵盖了 Agent 循环引擎、40 多个内置工具的完整实现、系统提示词的组装逻辑、记忆系统、上下文压缩、权限管控机制,还有一堆没上线的隐藏功能。但是不包括服务端的模型训练代码和 API 后端逻辑。整个项目用的是 React Ink 框架,简单说就是用 React 来写命令行界面,你可以理解为「在终端里写网页」。所以 Claude Code 的命令行交互才会比很多传统工具丝滑。我用 AI 把它的架构从上到下梳理了一遍,大致分为 6 层:1)最上面是 CLI 和界面层,你在终端里看到的所有交互都是这一层负责的2)往下是 Agent 循环引擎,你可以把它理解为 Claude Code 的大脑,所有的决策都从这里发出3)再往下是工具系统,40 多个内置工具加上 MCP 扩展4)然后是记忆系统,解决 AI 聊着聊着就断片儿的老毛病5)上下文压缩系统,解决 token 越来越贵、窗口越来越满的问题6)最底层是权限和安全系统接下来结合源码,看看每个模块具体是怎么实现的,Claude Code 是怎么做到这么好用的?一、Agent 循环大家都知道现在的 AI 编程工具早已经不是简单的「一问一答」了,而是能连续执行、自主完成任务的 AI Agent。可能有同学会觉得,这背后一定是什么特别复杂的架构,用了什么 AI Agent 开发框架、什么多 Agent 协作之类的吧?但我打开负责核心对话循环的 query.ts 文件一看,好家伙,最核心的代码其实就是一个 while(true) 无限循环!// query.ts async function* queryLoop(params: QueryParams, consumedCommandUuids: string[]) { let state: State = { messages: params.messages, toolUseContext: params.toolUseContext, autoCompactTracking: undefined, maxOutputTokensRecoveryCount: 0, hasAttemptedReactiveCompact: false, turnCount: 1, // ... } // eslint-disable-next-line no-constant-condition while (true) { // 1. 上下文压缩(防止 token 爆炸) // 2. 调用大模型,流式获取响应 // 3. 解析模型返回的工具调用 // 4. 执行工具,获取结果 // 5. 把结果追加到对话历史 // 6. 如果没有新的工具调用,结束;否则继续循环 } }就是这么朴素的一个循环。每一轮迭代里,程序先做上下文压缩、再调用大模型拿到响应,如果模型说「我要用某个工具」就去执行,把结果追加到对话历史里,然后进入下一轮,一直循环工作直到活儿干完了才停下来。这在 AI 领域叫 ReAct 机制(推理 + 执行),让 AI 自己形成「思考 → 行动 → 观察 → 再思考」的闭环。Claude Code 的源码就是这个理论最接地气的工程实现了。每次循环中,程序会通过 services/api/claude.ts 里的 queryModel 函数来跟大模型沟通。这个函数负责发送请求、接收 SSE 流式输出、累计 token 用量这些事情。模型返回的结果里如果包含 tool_use 类型的内容,说明 AI 还想调用工具继续干活,循环就接着转;如果没有 tool_use 了,说明任务做完了,循环就结束。// services/api/claude.ts — 模型调用核心函数 async function* queryModel( messages: Message[], systemPrompt: SystemPrompt, thinkingConfig: ThinkingConfig, tools: Tools, signal: AbortSignal, options: Options, ): AsyncGenerator<StreamEvent | AssistantMessage> { // 解析模型(含 Bedrock inference profile) // 合并 Beta headers // 构造 anthropic.beta.messages 流式请求 // 累计 token 用量 // yield 流式事件 }在这个循环定义的上方,还有一段 Anthropic 工程师留下的注释,叫什么「巫师守则」:// query.ts — queryLoop 函数上方 /** * The rules of thinking are lengthy and fortuitous... * * The rules follow: * 1. A message that contains a thinking block must be part of a query * whose max_thinking_length > 0 * 2. A thinking block may not be the last message in a block * 3. Thinking blocks must be preserved for the duration of an assistant * trajectory * * Heed these rules well, young wizard. For they are the rules of thinking, * and the rules of thinking are the rules of the universe. If ye does not * heed these rules, ye will be punished with an entire day of debugging * and hair pulling. */{dotted startColor="#ff6c6c" endColor="#fb9d18"/}这三条规则是关于模型思考过程(thinking block)的处理约束,大意如下思维准则思维的规则既冗长又充满偶然……规则如下:思维块(Thinking Block): 包含思维块的消息必须属于 max_thinking_length > 0 的查询请求。位置限制: 思维块不能作为消息序列中的最后一条消息。持久性: 在助手的整个对话轨迹(Trajectory)中,思维块必须全程保留。年轻的巫师,请务必恪守这些规则。因为思维的准则即是宇宙的准则。如果你不遵守,等待你的将是长达一整天痛苦的调试(Debugging)和抓狂(Hair pulling)。一时间分不清,这是程序员的浪漫,还是 AI 的浪漫?二、工具设计Claude Code 内置了 40 多个工具,在负责工具注册和管理的 tools.ts 文件里,有个 getAllBaseTools() 函数列出了所有内置工具:// tools.ts — 工具注册文件 /** * NOTE: This MUST stay in sync with https://console.statsig.com/... * in order to cache the system prompt across users. */ export function getAllBaseTools(): Tools { return [ AgentTool, // 子 Agent 生成 TaskOutputTool, // 任务输出 BashTool, // 执行终端命令 ...(hasEmbeddedSearchTools() ? [] : [GlobTool, GrepTool]), FileReadTool, // 读文件 FileEditTool, // 编辑文件 FileWriteTool, // 写文件 NotebookEditTool, // 编辑 Notebook WebFetchTool, // 网络请求 WebSearchTool, // 网络搜索 TodoWriteTool, // 待办事项 SkillTool, // 技能调用 EnterPlanModeTool, // 进入规划模式 ...(process.env.USER_TYPE === 'ant' ? [ConfigTool] : []), // ... 还有几十个,根据环境和 Feature Flag 动态加载 ...(isToolSearchEnabledOptimistic() ? [ToolSearchTool] : []), ] } 注意开头那段注释,意思是这份工具清单必须和他们的 A/B 测试配置中心保持同步,否则全球用户共享的系统提示词缓存就废了。看来工具注册不只是功能问题,还直接关系到成本和性能。还有最后一行的 ToolSearchTool,当用户接了很多 MCP 插件、工具数量特别多的时候,Claude Code 不会把所有工具的完整描述都塞进系统提示词里,而是先给模型一份「工具名 + 一句话介绍」的精简清单,让模型自己选需要哪些,再按需加载完整定义,从而节省了大量 token。代码里还能看到 process.env.USER_TYPE === 'ant' 这个判断,ant 是 Anthropic 内部员工的代号(蚂蚁),这说明 Anthropic 自己也在重度用 Claude Code 来开发 Claude Code,怪不得这源码一股 AI 味儿。每个具体的工具都是通过 Tool.ts 里的 buildTool 工厂函数创建的,这个函数有个很巧妙的 默认值设计:// Tool.ts — 工具类型定义和工厂函数 // Defaults (fail-closed where it matters): // - isConcurrencySafe → false (assume not safe) // - isReadOnly → false (assume writes) // - isDestructive → false // - toAutoClassifierInput → '' (skip classifier — security-relevant tools must override) const TOOL_DEFAULTS = { isEnabled: () => true, isConcurrencySafe: (_input?: unknown) => false, isReadOnly: (_input?: unknown) => false, isDestructive: (_input?: unknown) => false, toAutoClassifierInput: () => '', // ... }注释里写的 「fail-closed where it matters」 是什么意思呢?可以看到 isConcurrencySafe 和 isReadOnly 都默认为 false,也就是说如果某个工具的开发者忘了声明「我只是读个文件,不会改东西」,系统就自动把它当成危险操作处理,不让它并发执行。这种思路叫做 fail-closed(失败时关闭),打个比方就像公司的门禁系统,你没刷卡默认进不去;跟它相反的 fail-open 就像小区大门,谁来都让进。对于 AI 应用,你不知道它下一步会调用什么工具。在这种不确定性下,「默认禁止」比「默认允许」安全太多了。毕竟 Claude Code 直接操作你整个代码库,一旦出事儿可能是你半个月的代码白写了。还有 toAutoClassifierInput 默认返回空字符串,意味着默认跳过自动分类器检查,但注释专门强调了安全相关的工具必须自己重写这个方法。这也是 fail-closed 的思路。三、读写分离的工具并发假设 AI 同时想读 3 个文件、再改 1 个文件,这 4 个操作是一个一个排队跑、还是一起并发执行呢?Claude Code 在负责工具执行编排的 toolOrchestration.ts 里做了一套很聪明的读写分离机制。先看并发上限,默认最多 10 个工具同时并发,还可以通过环境变量调整:// services/tools/toolOrchestration.ts — 工具执行编排 function getMaxToolUseConcurrency(): number { return parseInt(process.env.CLAUDE_CODE_MAX_TOOL_USE_CONCURRENCY || '', 10) || 10 }然后是核心的分批逻辑:// services/tools/toolOrchestration.ts function partitionToolCalls(toolUseMessages, toolUseContext): Batch[] { return toolUseMessages.reduce((acc, toolUse) => { const tool = findToolByName(toolUseContext.options.tools, toolUse.name) const parsedInput = tool?.inputSchema.safeParse(toolUse.input) const isConcurrencySafe = parsedInput?.success ? (() => { try { return Boolean(tool?.isConcurrencySafe(parsedInput.data)) } catch { return false // 抛异常也当不安全,又是 fail-closed } })() : false // 解析失败也当不安全 if (isConcurrencySafe && acc[acc.length - 1]?.isConcurrencySafe) { acc[acc.length - 1].blocks.push(toolUse) // 合并到并发批次 } else { acc.push({ isConcurrencySafe, blocks: [toolUse] }) // 新开一个批次 } return acc }, []) }简单说就是连续几个只读工具可以一起跑,但一旦遇到写操作,就得排队等前面的都完成了才行。而且注意那个 try-catch,如果判断方法本身抛了异常(比如参数解析出错),也直接当不安全处理。并发执行完之后,产生的上下文修改 contextModifier 也不会立刻生效,而是先排队存着,等一个批次的所有工具都跑完了再按顺序依次应用。在工具执行编排文件的 runTools 函数里能看到这个逻辑:// services/tools/toolOrchestration.ts — runTools 函数 if (isConcurrencySafe) { const queuedContextModifiers = {} for await (const update of runToolsConcurrently(blocks, ...)) { if (update.contextModifier) { // 先排队,不立即应用 queuedContextModifiers[toolUseID].push(modifyContext) } } // 全部跑完后,按工具调用顺序依次应用 for (const block of blocks) { for (const modifier of queuedContextModifiers[block.id]) { currentContext = modifier(currentContext) } } }学过数据库的同学肯定觉得眼熟,这不就是「读读并行、读写互斥」的简化版嘛。很多计算机底层的设计思想,换个场景照样管用,这就是基础知识的魅力。四、System Prompt 的缓存分裂Anthropic 的 API 支持 Prompt Cache 提示词缓存,如果你每次发给模型的系统提示词前半部分都不变,API 就能缓存这部分内容,后续请求直接复用,不用重新处理。打开负责系统提示词组装的 constants/prompts.ts 文件,你会看到提示词被一个叫 DYNAMIC_BOUNDARY 的标记分成了上下两部分:// constants/prompts.ts — 系统提示词组装 export const SYSTEM_PROMPT_DYNAMIC_BOUNDARY = '__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__' sections = [ // ...静态部分:角色定义、行为规范、工具说明、语气要求等 // === BOUNDARY MARKER - DO NOT MOVE OR REMOVE === ...(shouldUseGlobalCacheScope() ? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []), // --- Dynamic content (registry-managed) --- ...resolvedDynamicSections, // 动态部分:当前时间、git 状态、CLAUDE.md 配置、MCP 工具等 ]Claude Code 用这条分界线精确地把提示词切成两半:上面是静态部分,全球几百万用户共享同一份缓存;下面是动态部分,比如你当前的时间、你的 Git 仓库状态、你自己配的 CLAUDE.md 规则等等,每个用户各不相同,独立加载。源码注释里还专门警告,如果把动态内容不小心混到了静态部分里,每个用户的提示词都不一样了,缓存就全废了。// constants/prompts.ts // WARNING: Do not remove or reorder this marker without updating cache logic in: // - src/utils/api.ts (splitSysPromptPrefix) // - src/services/api/claude.ts (buildSystemPromptBlocks)五、内容检索策略AI 模型本身没有你项目的代码记忆,所以需要一种方式让它「看到」相关的代码和文档。现在业界最流行的做法叫 RAG 检索增强生成,简单说就是先把项目数据做 Embedding 存到向量数据库里,用户提问时先从数据库里检索出相关内容,再连同问题一起发给模型回答。但没想到,Claude Code 压根不用这套!不管是搜记忆文件还是搜历史对话,它用的都是最朴素的 Grep 文本搜索。在负责记忆系统的 memdir/memdir.ts 文件里有个 buildSearchingPastContextSection 函数,写得很明确:// memdir/memdir.ts — 记忆搜索指令 const memSearch = `grep -rn "<search term>" ${autoMemDir} --include="*.md"` const transcriptSearch = `grep -rn "<search term>" ${projectDir}/ --include="*.jsonl"`Claude Code 的创始人 Boris Cherny 在播客里说过:俺们试过 RAG,但发现让 AI 自己决定搜什么、怎么搜,效果反而远远好于 RAG。我的理解是这样的,RAG 相当于你帮实习生把相关资料都整理好了打包给他看;而 Agentic Search 是直接给他公司文档库的权限,让他自己去找。模型能力越强,后者的优势就越大,因为 AI 比你更知道自己需要什么信息。而且 Grep 这种方案简单、没有索引过期问题、不用维护向量数据库,工程复杂度直接降了一个量级。所以做 AI 应用的时候,哪些能力该交给工程系统、哪些该留给 AI 模型,这个边界值得好好想想。模型越来越强,很多以前需要复杂工程方案解决的问题,现在可能直接让 AI 自己搞定就行了。六、三层记忆架构这是我觉得整份源码里设计最精妙的部分了,也是现在 Context Engineering 上下文工程领域最值得学的案例。用过 AI 编程工具的朋友应该都体验过:同一个对话框里聊久了,AI 就断片儿了,忘了之前说过什么,甚至自相矛盾。Claude Code 为了解决这个问题,搞了一套分层记忆系统,网上有人管它叫 Self-Healing Memory 自愈记忆。第一层、MEMORY.md(热数据,常驻加载)MEMORY.md 就像一本书的目录,每次对话都会加载到上下文里。看看 memdir/memdir.ts 文件里是怎么限制它的大小的:// memdir/memdir.ts — 记忆索引文件 export const ENTRYPOINT_NAME = 'MEMORY.md' export const MAX_ENTRYPOINT_LINES = 200 // ~125 chars/line at 200 lines. At p97 today; catches long-line indexes that // slip past the line cap (p100 observed: 197KB under 200 lines). export const MAX_ENTRYPOINT_BYTES = 25_000最多 200 行、25KB,而且只存指针不存内容,每行不超 150 字符。因为它每次都要占上下文窗口的位置,如果太大就会把有用的对话内容挤掉。注释里提到,25KB 那个字节限制是后来加的。因为他们发现有用户虽然没超 200 行,但每行写了一大堆,200 行居然能写到 197KB。所以不得不加个字节数的兜底保护。如果内容超出限制了怎么办?在这个文件里,还有一段详细的截断逻辑:// memdir/memdir.ts — 截断逻辑 export function truncateEntrypointContent(raw: string): EntrypointTruncation { // 先按行数截断 let truncated = wasLineTruncated ? contentLines.slice(0, MAX_ENTRYPOINT_LINES).join('\n') : trimmed // 再按字节数截断,在最后一个换行符处切,避免截断到一半 if (truncated.length > MAX_ENTRYPOINT_BYTES) { const cutAt = truncated.lastIndexOf('\n', MAX_ENTRYPOINT_BYTES) truncated = truncated.slice(0, cutAt > 0 ? cutAt : MAX_ENTRYPOINT_BYTES) } // 截断后追加 WARNING,让 AI 知道这个文件没加载完 return { content: truncated + `\n\n> WARNING: ${ENTRYPOINT_NAME} is ${reason}. Only part of it was loaded.`, } }采用行数截断 + 字节截断双保险,截断时还会在最后一个换行符处切开,不会切到一行的中间。截断之后还追加了一条 WARNING,让 AI 知道「这个索引没加载完整」。这种细节才是 Claude Code 体验好的原因。第二层、话题文件(温数据,按需加载)你的编码偏好、项目的架构约定、之前踩过的坑这些细节信息,都存在单独的话题文件里,比如 user_role.md、feedback_testing.md。新对话开始时,Claude Code 会用 Sonnet 小模型来挑选最多 5 个跟当前对话相关的文件加载进来。在负责记忆召回的 findRelevantMemories.ts 文件中,可以看到它挑选记忆的提示词:// memdir/findRelevantMemories.ts — 记忆召回 const SELECT_MEMORIES_SYSTEM_PROMPT = `You are selecting memories that will be useful to Claude Code as it processes a user's query. Return a list of filenames for the memories that will clearly be useful (up to 5). - If a list of recently-used tools is provided, do not select memories that are usage reference or API documentation for those tools (Claude Code is already exercising them). DO still select memories containing warnings, gotchas, or known issues about those tools — active use is exactly when those matter.`最后那条规则我觉得是 punchline:如果某个工具正在被使用,就不加载它的使用文档(你都在用了说明你会用),但一定要加载它的已知问题和坑。想想也对,你正在用一个东西的时候,最怕的不就是不知道有什么坑嘛。而且 Claude Code 的记忆 不记代码。因为代码会发生变化,但记忆并不会自动更新。举个例子,如果记忆里说「函数 X 在第 30 行」,你后来重构了,这条记忆就变成误导了。所以它只记人的偏好和判断,代码的事实永远去源码里实时读取。做过后端开发的朋友都知道,缓存和数据库不一致是最坑的 Bug 之一。Claude Code 的做法等于从根源上消灭了不一致的可能性。第三层、历史对话(冷数据,Grep 搜索)更早之前的历史对话会被存成 .jsonl 格式的文件,需要的时候用 Grep 搜关键词就能找到。总结一下,不同温度的数据用不同方式管理。热的常驻、温的按需、冷的搜索。如果你面试被问到 “AI 应用怎么做长期记忆”,这套方案绝对能让面试官眼前一亮,毕竟 Claude Code 这种级别的产品都在用。七、五级上下文压缩上一节讲的是记忆怎么存和取,这一节讲的是上下文怎么「瘦身」。大模型的上下文窗口是有上限的,随着对话越来越长、工具调用结果越攒越多,token 用量会快速膨胀,不仅费钱,还可能直接超出窗口限制导致请求失败。Claude Code 为了应对这个问题,设计了五级压缩策略,像漏斗一样层层过滤:Snip 剪裁:最轻的一刀,把旧的工具调用结果只保留结构,不保留内容Microcompact 微压缩:把体积大的工具执行结果卸载到缓存里。注意是卸载到缓存而不是直接丢掉,因为子智能体后续可能还需要这些结果Context Collapse 折叠:对中间的对话做折叠摘要,只保留关键信息Autocompact 自动压缩:当上下文占用超过阈值时,触发全量摘要压缩Reactive Compact 应急压缩:最后的兜底,当 API 返回 413 “提示词太长” 错误时紧急触发 这五级从轻到重依次触发,能裁掉的内容先裁掉,实在不够了再上更重的方案。从 query.ts 文件的开头可以看到其中三级压缩模块通过 Feature Flag 按需引入(另外两级在其他文件里):// query.ts — 压缩模块按需加载 const reactiveCompact = feature('REACTIVE_COMPACT') ? require('./services/compact/reactiveCompact.js') : null const contextCollapse = feature('CONTEXT_COLLAPSE') ? require('./services/contextCollapse/index.js') : null const snipModule = feature('HISTORY_SNIP') ? require('./services/compact/snipCompact.js') : null这里面还有个「断路器」机制让我印象深刻,在负责自动压缩的 services/compact/autoCompact.ts 文件里:// services/compact/autoCompact.ts — 断路器 // Stop trying autocompact after this many consecutive failures. // BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures // (up to 3,272) in a single session, wasting ~250K API calls/day globally. const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3看到注释中的那串数字了吗?2026 年 3 月 10 号他们统计发现有 1279 个会话连续压缩失败了 50 次以上,最夸张的一个会话连续失败了 3272 次还在不停重试,全球每天浪费 25 万次 API 调用!要是让我这种老倒霉蛋遇上了,光 token 费就够我吃一个月的了,这要是曝光出来公关团队怕是有的忙了……所以他们加了这个断路器,连续失败 3 次就自动停下来。八、安全审查用 Claude Code 的时候你可以开启 --dangerously-skip-permissions 模式(也叫 YOLO 模式),跳过所有权限确认,让 AI 自己干活。我之前一直以为这模式就是完全不设防了,看了源码才知道,其实背后还偷偷跑着一个「影子 AI」在帮你把关。源码里有个文件叫 utils/permissions/yoloClassifier.ts,每次主 AI 要执行操作,这个独立的 AI 分类器都会过一遍:// utils/permissions/yoloClassifier.ts — YOLO 安全分类器 export async function classifyYoloAction( toolName: string, toolInput: Record<string, unknown>, // ... ): Promise<'allow' | 'soft_deny' | 'hard_deny'> { // 用一个独立的模型来判断这个操作安不安全 // allow: 安全的,直接放行 // soft_deny: 有风险,降级成需要手动确认 // hard_deny: 直接拦截,没得商量 }而且权限系统不只有 YOLO Classifier 一个检查点。一次工具调用要过的关卡至少包括:你当前的运行模式(Plan / Auto / Bypass)用户在 hooks 里设的自定义规则YOLO Classifier 的模型分析Bash 命令危险度分类(像 rm -rf 这种直接拦截)配置文件里的规则引擎多个来源的权限结果还有竞争关系,最终取最严格的那个。 其中第 4 点 Bash 命令安全检查的严格程度远超我的预期。在 tools/BashTool/bashSecurity.ts 这个文件里,定义了 23 种 安全检查规则:// tools/BashTool/bashSecurity.ts — Bash 安全检查 ID const BASH_SECURITY_CHECK_IDS = { INCOMPLETE_COMMANDS: 1, // 残缺命令(以 tab 或 - 开头) JQ_SYSTEM_FUNCTION: 2, // jq 的 system() 函数调用 OBFUSCATED_FLAGS: 4, // 混淆的命令行参数 SHELL_METACHARACTERS: 5, // 危险的 shell 元字符 DANGEROUS_VARIABLES: 6, // 危险环境变量注入 IFS_INJECTION: 11, // IFS 变量注入 PROC_ENVIRON_ACCESS: 13, // /proc/environ 访问 CONTROL_CHARACTERS: 17, // 控制字符 UNICODE_WHITESPACE: 18, // Unicode 空白字符欺骗 ZSH_DANGEROUS_COMMANDS: 20, // Zsh 危险命令(zmodload 等) COMMENT_QUOTE_DESYNC: 22, // 注释与引号状态不同步 QUOTED_NEWLINE: 23, // 引号内换行 // ... 共 23 种 }比如第 18 条的 UNICODE_WHITESPACE,说明 Anthropic 的安全团队考虑过用 Unicode 零宽空格来混淆命令的攻击手法,让安全检查器看到的和 shell 实际执行的不是同一条命令。还有第 20 条针对 Zsh 的 zmodload 命令,这个命令能加载模块绕过常规的文件和网络检查,总之防护做的还是很周到的。怪不得我开着全部放行模式用了这么久,从来没出过什么严重事故,原来是有一套多层机制在背后替我负重前行。九、Feature Flag 和未来功能在 Claude Code 的源码中,你会经常看到 feature('XXX') 的判断:// tools.ts — Feature Flag 条件加载 const SleepTool = feature('PROACTIVE') || feature('KAIROS') ? require('./tools/SleepTool/SleepTool.js').SleepTool : null const WebBrowserTool = feature('WEB_BROWSER_TOOL') ? require('./tools/WebBrowserTool/WebBrowserTool.js').WebBrowserTool : null这就是 Feature Flag 功能开关,做开发的同学应该都不陌生。每个实验功能都藏在开关后面,可以按用户、按环境灰度发布。这样万一出了问题,就不用回滚代码,直接关掉开关就行。通过条件 require,关掉的功能在打包时还能被 tree-shaking 掉,不增加体积。有趣的是,这些 Feature Flag 等于无意中泄露了 Claude Code 的产品路线图:1)KAIROS:长期助手模式,AI 可以 24 小时持续运行不结束。里面还有个 AutoDream 自动做梦功能,名字起得很是浪漫,说白了就是 AI 白天干活记笔记,晚上自动整理记忆。2)COORDINATOR_MODE:多 Agent 协作,一个 AI 指挥多个 AI 干活。从 coordinatorMode.ts 能看到,它的工作流分四个阶段:// coordinator/coordinatorMode.ts — 协调者工作流定义 | Phase | Who | Purpose | |----------------|--------------------|---------------------------------------------------------| | Research | Workers (parallel) | Investigate codebase, find files, understand problem | | Synthesis | You (coordinator) | Read findings, craft implementation specs | | Implementation | Workers | Make targeted changes per spec, commit | | Verification | Workers | Test changes work |子智能体之间通过 utils/mailbox.ts 里的 Mailbox(一个基于文件的消息队列)来通信。还有 VOICE_MODE 语音模式、WEB_BROWSER_TOOL 浏览器操作工具等等。十、反蒸馏和卧底模式Anthropic 为了防止竞争对手窃取 Claude Code 的能力、以及防止内部信息通过开源贡献泄露,在源码里埋了两套防御机制。(但没想到这波泄露了个大的 😂)先说反蒸馏。有些竞争对手可能会通过录制 Claude Code 的 API 流量来「蒸馏」它的能力,就是把大模型的输入输出录下来,用来训练自己的小模型。Anthropic 的应对策略简直绝了,直接往 API 请求里注入假工具定义:// services/api/claude.ts — 负责模型 API 调用 // Anti-distillation: send fake_tools opt-in for 1P CLI only if (feature('ANTI_DISTILLATION_CC') && process.env.CLAUDE_CODE_ENTRYPOINT === 'cli' && shouldIncludeFirstPartyOnlyBetas() ) { result.anti_distillation = ['fake_tools'] }做防御不是单纯加密或者限速,而是主动给你喂假数据,让你拿去训练的模型越训越差,有点儿反间计的意思。而且它只在 Anthropic 官方的命令行客户端,也就是你在终端里直接用 claude 命令的场景中才生效,通过 SDK 或其他方式接入的不受影响。再说卧底模式,Anthropic 内部员工用 Claude Code 往开源项目提交代码时,会自动启用这个模式:// utils/undercover.ts — 负责隐藏 AI 贡献痕迹 /** * Undercover mode — safety utilities for contributing to public repos. * When active, Claude Code strips all attribution to avoid leaking internal * model codenames, project names, or other Anthropic-internal information. * The model is not told what model it is. * * There is NO force-OFF. This guards against model codename leaks. */ export function isUndercover(): boolean { if (process.env.USER_TYPE === 'ant') { if (isEnvTruthy(process.env.CLAUDE_CODE_UNDERCOVER)) return true // Auto: active unless we've confirmed we're in an internal repo. return getRepoClassCached() !== 'internal' } return false }注释里写得很明确:「There is NO force-OFF」,不能强制关闭。而且从代码逻辑看,默认就是开启的,只有当仓库被确认为内部仓库时才会关掉。说明 Anthropic 非常担心内部模型代号通过开源贡献泄露出去。十一、其他细节最后分享几个源码里藏着的有趣细节。1)在 buddy/ 目录下,Anthropic 的工程师居然偷偷藏了一套数字宠物系统!一共 18 种物种,从鸭子到仙人掌应有尽有:// buddy/types.ts — 虚拟宠物物种定义 export const SPECIES = [ duck, goose, blob, cat, dragon, octopus, owl, penguin, turtle, snail, ghost, axolotl, capybara, cactus, robot, rabbit, mushroom, chonk, ] as const这个功能原本计划 4 月份作为彩蛋预热、5 月正式上线,结果源码泄露了提前被大家发现了。AI 写代码写累了,然后撸撸 AI 宠物,Anthropic 的工程师也太会整活了。2)还有个小细节,因为 Claude 之前老是浪费一轮对话去执行 mkdir 检查目录存不存在,工程师们直接在 memdir/memdir.ts 里硬编码了一行提示,告诉 AI “这个目录已经存在了,直接用 Write 工具往里写就行,不要再跑 mkdir 或者检查目录是否存在了!”// memdir/memdir.ts // Shipped because Claude was burning turns on `ls`/`mkdir -p` before writing. export const DIR_EXISTS_GUIDANCE = 'This directory already exists — write to it directly with the Write tool (do not run mkdir or check for its existence).'3)Claude Code 对启动速度有一种近乎偏执的追求。比如在入口文件 cli.tsx 里,--version 这种最简单的请求一个模块都不加载,直接返回;其他路径全部用 await import() 动态加载,按需引入。更绝的是,在加载主模块的这几百毫秒里,它会同时启动一个「早期输入捕获器」(utils/earlyInput.ts),把你在等待时敲的键都缓存起来,模块加载完之后再回放,让你感觉 “刚敲完就有反应了”。初始化阶段还会偷偷发一个 TCP 预连接(utils/apiPreconnect.ts),让 TCP+TLS 握手和初始化工作并行跑,省掉 100ms 左右的等待时间。// utils/apiPreconnect.ts — TCP 预连接 /** * Preconnect to the Anthropic API to overlap TCP+TLS handshake with startup. * The TCP+TLS handshake is ~100-200ms that normally blocks inside the first * API call. Kicking a fire-and-forget fetch during init lets the handshake * happen in parallel with action-handler work. */最后看完这份源码,你会发现 Claude Code 里其实没什么惊天动地的新算法,用的基本上都是程序员接触过的基础知识,比如并发控制、读写分离、分层缓存、断路器、功能开关等等……但是 Claude Code 团队把这些东西组合到了 AI 场景里,打造出了一个极其优秀的产品,所以说计算机的基础知识和设计思想很重要。这份源码也是目前最好的 AI 应用架构教材了。像 Agent 循环怎么写、工具系统怎么设计、记忆怎么管理、安全怎么做,答案全在里面。简历上如果能写上 “深度阅读了 Claude Code 源码并应用于自己的项目”,那绝对是加分项。
Claude code 2026.3.31 文章by程序员鱼皮 文章内容来自程序员鱼皮文章链接 https://www.codefather.cn/post/2039551862717313025堪称全球最强的 AI 编程工具 Claude Code 的 50 多万行源码泄露了!一家以 AI 安全著称的公司,自己却在代码发布环节翻了车。到底是怎么泄露的Claude Code 是通过 npm 发布的,你可以把 npm 理解为程序员的「应用商店」,开发者把写好的工具打包上传到这里,别人一行命令就能安装。正常情况下,代码上线之前会经过「压缩混淆」处理,变成一坨人类看不懂的东西。在开发的时候,为了方便定位 Bug,代码打包工具会自动生成一个叫 Source Map 的文件,它相当于一张「翻译对照表」,能把加密后的代码还原成原始版本。但是这个文件只能在开发环境用,上线时必须删掉!结果 Anthropic 的工程师在发布 Claude Code 2.1.88 版本的时候,打包工具 Bun 默认生成了 Source Map 文件,而他们忘了在发布配置里把 .map 文件排除掉。于是一个 59.8 MB 的 cli.js.map 文件就这么被直接发到了公开的 npm 仓库。这个 map 文件本质上是一个 JSON,里面有两个关键数组,sources 存着所有文件的路径,sourcesContent 存着每个文件的完整源码,两者一一对应。只要写个脚本解析一下这个 JSON,按路径把内容写出来,所有源码就原样还原了。而且据说 map 文件里甚至还引用了一个 Cloudflare R2 存储桶的公开地址,点进去直接就能下载打包好的完整源码目录,连脚本都不用写。安全研究员 Chaofan Shou 最先发现了这个问题并发到了 X 上:然后几个小时之内 GitHub 上就冒出了好几个镜像仓库,源码传遍了整个互联网,其中有个仓库不到 1 天就快 10w Star 了(而且仓库里早就没有 Claude Code 源码了)……更搞笑的是,去年 2 月 Claude Code 刚发布的时候就出过一模一样的事故,同样的错误犯了两次!怕不是 Claude Code 团队的开发者 Vibe Coding 上瘾,连基本操作都忘了?源码里都有什么这次泄露的是 Claude Code 客户端的源码,包括 1906 个 TypeScript 源文件、大约 51.2 万行代码。涵盖了 Agent 循环引擎、40 多个内置工具的完整实现、系统提示词的组装逻辑、记忆系统、上下文压缩、权限管控机制,还有一堆没上线的隐藏功能。但是不包括服务端的模型训练代码和 API 后端逻辑。整个项目用的是 React Ink 框架,简单说就是用 React 来写命令行界面,你可以理解为「在终端里写网页」。所以 Claude Code 的命令行交互才会比很多传统工具丝滑。我用 AI 把它的架构从上到下梳理了一遍,大致分为 6 层:1)最上面是 CLI 和界面层,你在终端里看到的所有交互都是这一层负责的2)往下是 Agent 循环引擎,你可以把它理解为 Claude Code 的大脑,所有的决策都从这里发出3)再往下是工具系统,40 多个内置工具加上 MCP 扩展4)然后是记忆系统,解决 AI 聊着聊着就断片儿的老毛病5)上下文压缩系统,解决 token 越来越贵、窗口越来越满的问题6)最底层是权限和安全系统接下来结合源码,看看每个模块具体是怎么实现的,Claude Code 是怎么做到这么好用的?一、Agent 循环大家都知道现在的 AI 编程工具早已经不是简单的「一问一答」了,而是能连续执行、自主完成任务的 AI Agent。可能有同学会觉得,这背后一定是什么特别复杂的架构,用了什么 AI Agent 开发框架、什么多 Agent 协作之类的吧?但我打开负责核心对话循环的 query.ts 文件一看,好家伙,最核心的代码其实就是一个 while(true) 无限循环!// query.ts async function* queryLoop(params: QueryParams, consumedCommandUuids: string[]) { let state: State = { messages: params.messages, toolUseContext: params.toolUseContext, autoCompactTracking: undefined, maxOutputTokensRecoveryCount: 0, hasAttemptedReactiveCompact: false, turnCount: 1, // ... } // eslint-disable-next-line no-constant-condition while (true) { // 1. 上下文压缩(防止 token 爆炸) // 2. 调用大模型,流式获取响应 // 3. 解析模型返回的工具调用 // 4. 执行工具,获取结果 // 5. 把结果追加到对话历史 // 6. 如果没有新的工具调用,结束;否则继续循环 } }就是这么朴素的一个循环。每一轮迭代里,程序先做上下文压缩、再调用大模型拿到响应,如果模型说「我要用某个工具」就去执行,把结果追加到对话历史里,然后进入下一轮,一直循环工作直到活儿干完了才停下来。这在 AI 领域叫 ReAct 机制(推理 + 执行),让 AI 自己形成「思考 → 行动 → 观察 → 再思考」的闭环。Claude Code 的源码就是这个理论最接地气的工程实现了。每次循环中,程序会通过 services/api/claude.ts 里的 queryModel 函数来跟大模型沟通。这个函数负责发送请求、接收 SSE 流式输出、累计 token 用量这些事情。模型返回的结果里如果包含 tool_use 类型的内容,说明 AI 还想调用工具继续干活,循环就接着转;如果没有 tool_use 了,说明任务做完了,循环就结束。// services/api/claude.ts — 模型调用核心函数 async function* queryModel( messages: Message[], systemPrompt: SystemPrompt, thinkingConfig: ThinkingConfig, tools: Tools, signal: AbortSignal, options: Options, ): AsyncGenerator<StreamEvent | AssistantMessage> { // 解析模型(含 Bedrock inference profile) // 合并 Beta headers // 构造 anthropic.beta.messages 流式请求 // 累计 token 用量 // yield 流式事件 }在这个循环定义的上方,还有一段 Anthropic 工程师留下的注释,叫什么「巫师守则」:// query.ts — queryLoop 函数上方 /** * The rules of thinking are lengthy and fortuitous... * * The rules follow: * 1. A message that contains a thinking block must be part of a query * whose max_thinking_length > 0 * 2. A thinking block may not be the last message in a block * 3. Thinking blocks must be preserved for the duration of an assistant * trajectory * * Heed these rules well, young wizard. For they are the rules of thinking, * and the rules of thinking are the rules of the universe. If ye does not * heed these rules, ye will be punished with an entire day of debugging * and hair pulling. */{dotted startColor="#ff6c6c" endColor="#fb9d18"/}这三条规则是关于模型思考过程(thinking block)的处理约束,大意如下思维准则思维的规则既冗长又充满偶然……规则如下:思维块(Thinking Block): 包含思维块的消息必须属于 max_thinking_length > 0 的查询请求。位置限制: 思维块不能作为消息序列中的最后一条消息。持久性: 在助手的整个对话轨迹(Trajectory)中,思维块必须全程保留。年轻的巫师,请务必恪守这些规则。因为思维的准则即是宇宙的准则。如果你不遵守,等待你的将是长达一整天痛苦的调试(Debugging)和抓狂(Hair pulling)。一时间分不清,这是程序员的浪漫,还是 AI 的浪漫?二、工具设计Claude Code 内置了 40 多个工具,在负责工具注册和管理的 tools.ts 文件里,有个 getAllBaseTools() 函数列出了所有内置工具:// tools.ts — 工具注册文件 /** * NOTE: This MUST stay in sync with https://console.statsig.com/... * in order to cache the system prompt across users. */ export function getAllBaseTools(): Tools { return [ AgentTool, // 子 Agent 生成 TaskOutputTool, // 任务输出 BashTool, // 执行终端命令 ...(hasEmbeddedSearchTools() ? [] : [GlobTool, GrepTool]), FileReadTool, // 读文件 FileEditTool, // 编辑文件 FileWriteTool, // 写文件 NotebookEditTool, // 编辑 Notebook WebFetchTool, // 网络请求 WebSearchTool, // 网络搜索 TodoWriteTool, // 待办事项 SkillTool, // 技能调用 EnterPlanModeTool, // 进入规划模式 ...(process.env.USER_TYPE === 'ant' ? [ConfigTool] : []), // ... 还有几十个,根据环境和 Feature Flag 动态加载 ...(isToolSearchEnabledOptimistic() ? [ToolSearchTool] : []), ] } 注意开头那段注释,意思是这份工具清单必须和他们的 A/B 测试配置中心保持同步,否则全球用户共享的系统提示词缓存就废了。看来工具注册不只是功能问题,还直接关系到成本和性能。还有最后一行的 ToolSearchTool,当用户接了很多 MCP 插件、工具数量特别多的时候,Claude Code 不会把所有工具的完整描述都塞进系统提示词里,而是先给模型一份「工具名 + 一句话介绍」的精简清单,让模型自己选需要哪些,再按需加载完整定义,从而节省了大量 token。代码里还能看到 process.env.USER_TYPE === 'ant' 这个判断,ant 是 Anthropic 内部员工的代号(蚂蚁),这说明 Anthropic 自己也在重度用 Claude Code 来开发 Claude Code,怪不得这源码一股 AI 味儿。每个具体的工具都是通过 Tool.ts 里的 buildTool 工厂函数创建的,这个函数有个很巧妙的 默认值设计:// Tool.ts — 工具类型定义和工厂函数 // Defaults (fail-closed where it matters): // - isConcurrencySafe → false (assume not safe) // - isReadOnly → false (assume writes) // - isDestructive → false // - toAutoClassifierInput → '' (skip classifier — security-relevant tools must override) const TOOL_DEFAULTS = { isEnabled: () => true, isConcurrencySafe: (_input?: unknown) => false, isReadOnly: (_input?: unknown) => false, isDestructive: (_input?: unknown) => false, toAutoClassifierInput: () => '', // ... }注释里写的 「fail-closed where it matters」 是什么意思呢?可以看到 isConcurrencySafe 和 isReadOnly 都默认为 false,也就是说如果某个工具的开发者忘了声明「我只是读个文件,不会改东西」,系统就自动把它当成危险操作处理,不让它并发执行。这种思路叫做 fail-closed(失败时关闭),打个比方就像公司的门禁系统,你没刷卡默认进不去;跟它相反的 fail-open 就像小区大门,谁来都让进。对于 AI 应用,你不知道它下一步会调用什么工具。在这种不确定性下,「默认禁止」比「默认允许」安全太多了。毕竟 Claude Code 直接操作你整个代码库,一旦出事儿可能是你半个月的代码白写了。还有 toAutoClassifierInput 默认返回空字符串,意味着默认跳过自动分类器检查,但注释专门强调了安全相关的工具必须自己重写这个方法。这也是 fail-closed 的思路。三、读写分离的工具并发假设 AI 同时想读 3 个文件、再改 1 个文件,这 4 个操作是一个一个排队跑、还是一起并发执行呢?Claude Code 在负责工具执行编排的 toolOrchestration.ts 里做了一套很聪明的读写分离机制。先看并发上限,默认最多 10 个工具同时并发,还可以通过环境变量调整:// services/tools/toolOrchestration.ts — 工具执行编排 function getMaxToolUseConcurrency(): number { return parseInt(process.env.CLAUDE_CODE_MAX_TOOL_USE_CONCURRENCY || '', 10) || 10 }然后是核心的分批逻辑:// services/tools/toolOrchestration.ts function partitionToolCalls(toolUseMessages, toolUseContext): Batch[] { return toolUseMessages.reduce((acc, toolUse) => { const tool = findToolByName(toolUseContext.options.tools, toolUse.name) const parsedInput = tool?.inputSchema.safeParse(toolUse.input) const isConcurrencySafe = parsedInput?.success ? (() => { try { return Boolean(tool?.isConcurrencySafe(parsedInput.data)) } catch { return false // 抛异常也当不安全,又是 fail-closed } })() : false // 解析失败也当不安全 if (isConcurrencySafe && acc[acc.length - 1]?.isConcurrencySafe) { acc[acc.length - 1].blocks.push(toolUse) // 合并到并发批次 } else { acc.push({ isConcurrencySafe, blocks: [toolUse] }) // 新开一个批次 } return acc }, []) }简单说就是连续几个只读工具可以一起跑,但一旦遇到写操作,就得排队等前面的都完成了才行。而且注意那个 try-catch,如果判断方法本身抛了异常(比如参数解析出错),也直接当不安全处理。并发执行完之后,产生的上下文修改 contextModifier 也不会立刻生效,而是先排队存着,等一个批次的所有工具都跑完了再按顺序依次应用。在工具执行编排文件的 runTools 函数里能看到这个逻辑:// services/tools/toolOrchestration.ts — runTools 函数 if (isConcurrencySafe) { const queuedContextModifiers = {} for await (const update of runToolsConcurrently(blocks, ...)) { if (update.contextModifier) { // 先排队,不立即应用 queuedContextModifiers[toolUseID].push(modifyContext) } } // 全部跑完后,按工具调用顺序依次应用 for (const block of blocks) { for (const modifier of queuedContextModifiers[block.id]) { currentContext = modifier(currentContext) } } }学过数据库的同学肯定觉得眼熟,这不就是「读读并行、读写互斥」的简化版嘛。很多计算机底层的设计思想,换个场景照样管用,这就是基础知识的魅力。四、System Prompt 的缓存分裂Anthropic 的 API 支持 Prompt Cache 提示词缓存,如果你每次发给模型的系统提示词前半部分都不变,API 就能缓存这部分内容,后续请求直接复用,不用重新处理。打开负责系统提示词组装的 constants/prompts.ts 文件,你会看到提示词被一个叫 DYNAMIC_BOUNDARY 的标记分成了上下两部分:// constants/prompts.ts — 系统提示词组装 export const SYSTEM_PROMPT_DYNAMIC_BOUNDARY = '__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__' sections = [ // ...静态部分:角色定义、行为规范、工具说明、语气要求等 // === BOUNDARY MARKER - DO NOT MOVE OR REMOVE === ...(shouldUseGlobalCacheScope() ? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []), // --- Dynamic content (registry-managed) --- ...resolvedDynamicSections, // 动态部分:当前时间、git 状态、CLAUDE.md 配置、MCP 工具等 ]Claude Code 用这条分界线精确地把提示词切成两半:上面是静态部分,全球几百万用户共享同一份缓存;下面是动态部分,比如你当前的时间、你的 Git 仓库状态、你自己配的 CLAUDE.md 规则等等,每个用户各不相同,独立加载。源码注释里还专门警告,如果把动态内容不小心混到了静态部分里,每个用户的提示词都不一样了,缓存就全废了。// constants/prompts.ts // WARNING: Do not remove or reorder this marker without updating cache logic in: // - src/utils/api.ts (splitSysPromptPrefix) // - src/services/api/claude.ts (buildSystemPromptBlocks)五、内容检索策略AI 模型本身没有你项目的代码记忆,所以需要一种方式让它「看到」相关的代码和文档。现在业界最流行的做法叫 RAG 检索增强生成,简单说就是先把项目数据做 Embedding 存到向量数据库里,用户提问时先从数据库里检索出相关内容,再连同问题一起发给模型回答。但没想到,Claude Code 压根不用这套!不管是搜记忆文件还是搜历史对话,它用的都是最朴素的 Grep 文本搜索。在负责记忆系统的 memdir/memdir.ts 文件里有个 buildSearchingPastContextSection 函数,写得很明确:// memdir/memdir.ts — 记忆搜索指令 const memSearch = `grep -rn "<search term>" ${autoMemDir} --include="*.md"` const transcriptSearch = `grep -rn "<search term>" ${projectDir}/ --include="*.jsonl"`Claude Code 的创始人 Boris Cherny 在播客里说过:俺们试过 RAG,但发现让 AI 自己决定搜什么、怎么搜,效果反而远远好于 RAG。我的理解是这样的,RAG 相当于你帮实习生把相关资料都整理好了打包给他看;而 Agentic Search 是直接给他公司文档库的权限,让他自己去找。模型能力越强,后者的优势就越大,因为 AI 比你更知道自己需要什么信息。而且 Grep 这种方案简单、没有索引过期问题、不用维护向量数据库,工程复杂度直接降了一个量级。所以做 AI 应用的时候,哪些能力该交给工程系统、哪些该留给 AI 模型,这个边界值得好好想想。模型越来越强,很多以前需要复杂工程方案解决的问题,现在可能直接让 AI 自己搞定就行了。六、三层记忆架构这是我觉得整份源码里设计最精妙的部分了,也是现在 Context Engineering 上下文工程领域最值得学的案例。用过 AI 编程工具的朋友应该都体验过:同一个对话框里聊久了,AI 就断片儿了,忘了之前说过什么,甚至自相矛盾。Claude Code 为了解决这个问题,搞了一套分层记忆系统,网上有人管它叫 Self-Healing Memory 自愈记忆。第一层、MEMORY.md(热数据,常驻加载)MEMORY.md 就像一本书的目录,每次对话都会加载到上下文里。看看 memdir/memdir.ts 文件里是怎么限制它的大小的:// memdir/memdir.ts — 记忆索引文件 export const ENTRYPOINT_NAME = 'MEMORY.md' export const MAX_ENTRYPOINT_LINES = 200 // ~125 chars/line at 200 lines. At p97 today; catches long-line indexes that // slip past the line cap (p100 observed: 197KB under 200 lines). export const MAX_ENTRYPOINT_BYTES = 25_000最多 200 行、25KB,而且只存指针不存内容,每行不超 150 字符。因为它每次都要占上下文窗口的位置,如果太大就会把有用的对话内容挤掉。注释里提到,25KB 那个字节限制是后来加的。因为他们发现有用户虽然没超 200 行,但每行写了一大堆,200 行居然能写到 197KB。所以不得不加个字节数的兜底保护。如果内容超出限制了怎么办?在这个文件里,还有一段详细的截断逻辑:// memdir/memdir.ts — 截断逻辑 export function truncateEntrypointContent(raw: string): EntrypointTruncation { // 先按行数截断 let truncated = wasLineTruncated ? contentLines.slice(0, MAX_ENTRYPOINT_LINES).join('\n') : trimmed // 再按字节数截断,在最后一个换行符处切,避免截断到一半 if (truncated.length > MAX_ENTRYPOINT_BYTES) { const cutAt = truncated.lastIndexOf('\n', MAX_ENTRYPOINT_BYTES) truncated = truncated.slice(0, cutAt > 0 ? cutAt : MAX_ENTRYPOINT_BYTES) } // 截断后追加 WARNING,让 AI 知道这个文件没加载完 return { content: truncated + `\n\n> WARNING: ${ENTRYPOINT_NAME} is ${reason}. Only part of it was loaded.`, } }采用行数截断 + 字节截断双保险,截断时还会在最后一个换行符处切开,不会切到一行的中间。截断之后还追加了一条 WARNING,让 AI 知道「这个索引没加载完整」。这种细节才是 Claude Code 体验好的原因。第二层、话题文件(温数据,按需加载)你的编码偏好、项目的架构约定、之前踩过的坑这些细节信息,都存在单独的话题文件里,比如 user_role.md、feedback_testing.md。新对话开始时,Claude Code 会用 Sonnet 小模型来挑选最多 5 个跟当前对话相关的文件加载进来。在负责记忆召回的 findRelevantMemories.ts 文件中,可以看到它挑选记忆的提示词:// memdir/findRelevantMemories.ts — 记忆召回 const SELECT_MEMORIES_SYSTEM_PROMPT = `You are selecting memories that will be useful to Claude Code as it processes a user's query. Return a list of filenames for the memories that will clearly be useful (up to 5). - If a list of recently-used tools is provided, do not select memories that are usage reference or API documentation for those tools (Claude Code is already exercising them). DO still select memories containing warnings, gotchas, or known issues about those tools — active use is exactly when those matter.`最后那条规则我觉得是 punchline:如果某个工具正在被使用,就不加载它的使用文档(你都在用了说明你会用),但一定要加载它的已知问题和坑。想想也对,你正在用一个东西的时候,最怕的不就是不知道有什么坑嘛。而且 Claude Code 的记忆 不记代码。因为代码会发生变化,但记忆并不会自动更新。举个例子,如果记忆里说「函数 X 在第 30 行」,你后来重构了,这条记忆就变成误导了。所以它只记人的偏好和判断,代码的事实永远去源码里实时读取。做过后端开发的朋友都知道,缓存和数据库不一致是最坑的 Bug 之一。Claude Code 的做法等于从根源上消灭了不一致的可能性。第三层、历史对话(冷数据,Grep 搜索)更早之前的历史对话会被存成 .jsonl 格式的文件,需要的时候用 Grep 搜关键词就能找到。总结一下,不同温度的数据用不同方式管理。热的常驻、温的按需、冷的搜索。如果你面试被问到 “AI 应用怎么做长期记忆”,这套方案绝对能让面试官眼前一亮,毕竟 Claude Code 这种级别的产品都在用。七、五级上下文压缩上一节讲的是记忆怎么存和取,这一节讲的是上下文怎么「瘦身」。大模型的上下文窗口是有上限的,随着对话越来越长、工具调用结果越攒越多,token 用量会快速膨胀,不仅费钱,还可能直接超出窗口限制导致请求失败。Claude Code 为了应对这个问题,设计了五级压缩策略,像漏斗一样层层过滤:Snip 剪裁:最轻的一刀,把旧的工具调用结果只保留结构,不保留内容Microcompact 微压缩:把体积大的工具执行结果卸载到缓存里。注意是卸载到缓存而不是直接丢掉,因为子智能体后续可能还需要这些结果Context Collapse 折叠:对中间的对话做折叠摘要,只保留关键信息Autocompact 自动压缩:当上下文占用超过阈值时,触发全量摘要压缩Reactive Compact 应急压缩:最后的兜底,当 API 返回 413 “提示词太长” 错误时紧急触发 这五级从轻到重依次触发,能裁掉的内容先裁掉,实在不够了再上更重的方案。从 query.ts 文件的开头可以看到其中三级压缩模块通过 Feature Flag 按需引入(另外两级在其他文件里):// query.ts — 压缩模块按需加载 const reactiveCompact = feature('REACTIVE_COMPACT') ? require('./services/compact/reactiveCompact.js') : null const contextCollapse = feature('CONTEXT_COLLAPSE') ? require('./services/contextCollapse/index.js') : null const snipModule = feature('HISTORY_SNIP') ? require('./services/compact/snipCompact.js') : null这里面还有个「断路器」机制让我印象深刻,在负责自动压缩的 services/compact/autoCompact.ts 文件里:// services/compact/autoCompact.ts — 断路器 // Stop trying autocompact after this many consecutive failures. // BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures // (up to 3,272) in a single session, wasting ~250K API calls/day globally. const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3看到注释中的那串数字了吗?2026 年 3 月 10 号他们统计发现有 1279 个会话连续压缩失败了 50 次以上,最夸张的一个会话连续失败了 3272 次还在不停重试,全球每天浪费 25 万次 API 调用!要是让我这种老倒霉蛋遇上了,光 token 费就够我吃一个月的了,这要是曝光出来公关团队怕是有的忙了……所以他们加了这个断路器,连续失败 3 次就自动停下来。八、安全审查用 Claude Code 的时候你可以开启 --dangerously-skip-permissions 模式(也叫 YOLO 模式),跳过所有权限确认,让 AI 自己干活。我之前一直以为这模式就是完全不设防了,看了源码才知道,其实背后还偷偷跑着一个「影子 AI」在帮你把关。源码里有个文件叫 utils/permissions/yoloClassifier.ts,每次主 AI 要执行操作,这个独立的 AI 分类器都会过一遍:// utils/permissions/yoloClassifier.ts — YOLO 安全分类器 export async function classifyYoloAction( toolName: string, toolInput: Record<string, unknown>, // ... ): Promise<'allow' | 'soft_deny' | 'hard_deny'> { // 用一个独立的模型来判断这个操作安不安全 // allow: 安全的,直接放行 // soft_deny: 有风险,降级成需要手动确认 // hard_deny: 直接拦截,没得商量 }而且权限系统不只有 YOLO Classifier 一个检查点。一次工具调用要过的关卡至少包括:你当前的运行模式(Plan / Auto / Bypass)用户在 hooks 里设的自定义规则YOLO Classifier 的模型分析Bash 命令危险度分类(像 rm -rf 这种直接拦截)配置文件里的规则引擎多个来源的权限结果还有竞争关系,最终取最严格的那个。 其中第 4 点 Bash 命令安全检查的严格程度远超我的预期。在 tools/BashTool/bashSecurity.ts 这个文件里,定义了 23 种 安全检查规则:// tools/BashTool/bashSecurity.ts — Bash 安全检查 ID const BASH_SECURITY_CHECK_IDS = { INCOMPLETE_COMMANDS: 1, // 残缺命令(以 tab 或 - 开头) JQ_SYSTEM_FUNCTION: 2, // jq 的 system() 函数调用 OBFUSCATED_FLAGS: 4, // 混淆的命令行参数 SHELL_METACHARACTERS: 5, // 危险的 shell 元字符 DANGEROUS_VARIABLES: 6, // 危险环境变量注入 IFS_INJECTION: 11, // IFS 变量注入 PROC_ENVIRON_ACCESS: 13, // /proc/environ 访问 CONTROL_CHARACTERS: 17, // 控制字符 UNICODE_WHITESPACE: 18, // Unicode 空白字符欺骗 ZSH_DANGEROUS_COMMANDS: 20, // Zsh 危险命令(zmodload 等) COMMENT_QUOTE_DESYNC: 22, // 注释与引号状态不同步 QUOTED_NEWLINE: 23, // 引号内换行 // ... 共 23 种 }比如第 18 条的 UNICODE_WHITESPACE,说明 Anthropic 的安全团队考虑过用 Unicode 零宽空格来混淆命令的攻击手法,让安全检查器看到的和 shell 实际执行的不是同一条命令。还有第 20 条针对 Zsh 的 zmodload 命令,这个命令能加载模块绕过常规的文件和网络检查,总之防护做的还是很周到的。怪不得我开着全部放行模式用了这么久,从来没出过什么严重事故,原来是有一套多层机制在背后替我负重前行。九、Feature Flag 和未来功能在 Claude Code 的源码中,你会经常看到 feature('XXX') 的判断:// tools.ts — Feature Flag 条件加载 const SleepTool = feature('PROACTIVE') || feature('KAIROS') ? require('./tools/SleepTool/SleepTool.js').SleepTool : null const WebBrowserTool = feature('WEB_BROWSER_TOOL') ? require('./tools/WebBrowserTool/WebBrowserTool.js').WebBrowserTool : null这就是 Feature Flag 功能开关,做开发的同学应该都不陌生。每个实验功能都藏在开关后面,可以按用户、按环境灰度发布。这样万一出了问题,就不用回滚代码,直接关掉开关就行。通过条件 require,关掉的功能在打包时还能被 tree-shaking 掉,不增加体积。有趣的是,这些 Feature Flag 等于无意中泄露了 Claude Code 的产品路线图:1)KAIROS:长期助手模式,AI 可以 24 小时持续运行不结束。里面还有个 AutoDream 自动做梦功能,名字起得很是浪漫,说白了就是 AI 白天干活记笔记,晚上自动整理记忆。2)COORDINATOR_MODE:多 Agent 协作,一个 AI 指挥多个 AI 干活。从 coordinatorMode.ts 能看到,它的工作流分四个阶段:// coordinator/coordinatorMode.ts — 协调者工作流定义 | Phase | Who | Purpose | |----------------|--------------------|---------------------------------------------------------| | Research | Workers (parallel) | Investigate codebase, find files, understand problem | | Synthesis | You (coordinator) | Read findings, craft implementation specs | | Implementation | Workers | Make targeted changes per spec, commit | | Verification | Workers | Test changes work |子智能体之间通过 utils/mailbox.ts 里的 Mailbox(一个基于文件的消息队列)来通信。还有 VOICE_MODE 语音模式、WEB_BROWSER_TOOL 浏览器操作工具等等。十、反蒸馏和卧底模式Anthropic 为了防止竞争对手窃取 Claude Code 的能力、以及防止内部信息通过开源贡献泄露,在源码里埋了两套防御机制。(但没想到这波泄露了个大的 😂)先说反蒸馏。有些竞争对手可能会通过录制 Claude Code 的 API 流量来「蒸馏」它的能力,就是把大模型的输入输出录下来,用来训练自己的小模型。Anthropic 的应对策略简直绝了,直接往 API 请求里注入假工具定义:// services/api/claude.ts — 负责模型 API 调用 // Anti-distillation: send fake_tools opt-in for 1P CLI only if (feature('ANTI_DISTILLATION_CC') && process.env.CLAUDE_CODE_ENTRYPOINT === 'cli' && shouldIncludeFirstPartyOnlyBetas() ) { result.anti_distillation = ['fake_tools'] }做防御不是单纯加密或者限速,而是主动给你喂假数据,让你拿去训练的模型越训越差,有点儿反间计的意思。而且它只在 Anthropic 官方的命令行客户端,也就是你在终端里直接用 claude 命令的场景中才生效,通过 SDK 或其他方式接入的不受影响。再说卧底模式,Anthropic 内部员工用 Claude Code 往开源项目提交代码时,会自动启用这个模式:// utils/undercover.ts — 负责隐藏 AI 贡献痕迹 /** * Undercover mode — safety utilities for contributing to public repos. * When active, Claude Code strips all attribution to avoid leaking internal * model codenames, project names, or other Anthropic-internal information. * The model is not told what model it is. * * There is NO force-OFF. This guards against model codename leaks. */ export function isUndercover(): boolean { if (process.env.USER_TYPE === 'ant') { if (isEnvTruthy(process.env.CLAUDE_CODE_UNDERCOVER)) return true // Auto: active unless we've confirmed we're in an internal repo. return getRepoClassCached() !== 'internal' } return false }注释里写得很明确:「There is NO force-OFF」,不能强制关闭。而且从代码逻辑看,默认就是开启的,只有当仓库被确认为内部仓库时才会关掉。说明 Anthropic 非常担心内部模型代号通过开源贡献泄露出去。十一、其他细节最后分享几个源码里藏着的有趣细节。1)在 buddy/ 目录下,Anthropic 的工程师居然偷偷藏了一套数字宠物系统!一共 18 种物种,从鸭子到仙人掌应有尽有:// buddy/types.ts — 虚拟宠物物种定义 export const SPECIES = [ duck, goose, blob, cat, dragon, octopus, owl, penguin, turtle, snail, ghost, axolotl, capybara, cactus, robot, rabbit, mushroom, chonk, ] as const这个功能原本计划 4 月份作为彩蛋预热、5 月正式上线,结果源码泄露了提前被大家发现了。AI 写代码写累了,然后撸撸 AI 宠物,Anthropic 的工程师也太会整活了。2)还有个小细节,因为 Claude 之前老是浪费一轮对话去执行 mkdir 检查目录存不存在,工程师们直接在 memdir/memdir.ts 里硬编码了一行提示,告诉 AI “这个目录已经存在了,直接用 Write 工具往里写就行,不要再跑 mkdir 或者检查目录是否存在了!”// memdir/memdir.ts // Shipped because Claude was burning turns on `ls`/`mkdir -p` before writing. export const DIR_EXISTS_GUIDANCE = 'This directory already exists — write to it directly with the Write tool (do not run mkdir or check for its existence).'3)Claude Code 对启动速度有一种近乎偏执的追求。比如在入口文件 cli.tsx 里,--version 这种最简单的请求一个模块都不加载,直接返回;其他路径全部用 await import() 动态加载,按需引入。更绝的是,在加载主模块的这几百毫秒里,它会同时启动一个「早期输入捕获器」(utils/earlyInput.ts),把你在等待时敲的键都缓存起来,模块加载完之后再回放,让你感觉 “刚敲完就有反应了”。初始化阶段还会偷偷发一个 TCP 预连接(utils/apiPreconnect.ts),让 TCP+TLS 握手和初始化工作并行跑,省掉 100ms 左右的等待时间。// utils/apiPreconnect.ts — TCP 预连接 /** * Preconnect to the Anthropic API to overlap TCP+TLS handshake with startup. * The TCP+TLS handshake is ~100-200ms that normally blocks inside the first * API call. Kicking a fire-and-forget fetch during init lets the handshake * happen in parallel with action-handler work. */最后看完这份源码,你会发现 Claude Code 里其实没什么惊天动地的新算法,用的基本上都是程序员接触过的基础知识,比如并发控制、读写分离、分层缓存、断路器、功能开关等等……但是 Claude Code 团队把这些东西组合到了 AI 场景里,打造出了一个极其优秀的产品,所以说计算机的基础知识和设计思想很重要。这份源码也是目前最好的 AI 应用架构教材了。像 Agent 循环怎么写、工具系统怎么设计、记忆怎么管理、安全怎么做,答案全在里面。简历上如果能写上 “深度阅读了 Claude Code 源码并应用于自己的项目”,那绝对是加分项。 -
Node.js—Express使用 前言 前端也是可以编写接口的噢,我们一步一步学下去吧。Express 安装首先假定你已经安装了 Node.js,接下来为你的应用创建一个目录,然后进入此目录并将其作为当前工作目录。代码语言:javascriptAI代码解释$ mkdir myapp$ cd myapp通过 npm init 命令为你的应用创建一个 package.json 文件。代码语言:javascriptAI代码解释$ npm init此命令将要求你输入几个参数,例如此应用的名称和版本。 你可以直接按“回车”键接受大部分默认设置即可,下面这个除外:entry point: (index.js)键入 app.js 或者你所希望的名称,这是当前应用的入口文件。如果你希望采用默认的 index.js 文件名,只需按“回车”键即可。接下来在 myapp 目录下安装 Express 并将其保存到依赖列表中。如下:代码语言:javascriptAI代码解释$ npm install express --save如果只是临时安装 Express,不想将它添加到依赖列表中,可执行如下命令:代码语言:javascriptAI代码解释$ npm install express --no-save安装nodemon工具为什么要使用nodemon在编写调试 Node.js项目的时候,如果修改了项目的代码,则需要频繁的手动close掉,然后再重新启动,非常繁琐.。现在,我们可以使用nodemon (https/www.npmjs.com/package/nodemon)这个工具,它能够监听项目文件的变动,当代码被修改后,nodemon 会自动帮我们重启项目。极大方便了开发和调试。安装代码语言:javascriptAI代码解释npm i -g nodemon使用nodemon第一个案例体验代码语言:javascriptAI代码解释const express = require('express') // => 引入 express 模块const app = express() // => 实例化模块const port = 8080 // => 定义端口变量app.get('/', (req, res) => { res.send('Hello World!')})app.listen(port, () => { console.log(Example app listening on port ${port})})如上就是一个使用 express 创建的最基本的web服务器第五行中 '/',指的是根目录,可以理解为什么都没带,就比如我是8080端口打开,那么此时的地址栏为 http://localhost:8080/。req指的是请求,res指的是响应。现在站在服务端的视角来看:req是前端传过来的,res是响应返回给前端的。第九行中调用app.listen方法,启动服务器,是监听了port这个端口号,监听成功后执行回调。Express基本使用之监听请求监听get请求通过 app.get() 方法,可以监听客户端的GET请求,具体语法格式如下:监听post请求将内容响应给客户端通过res.send()方法,可以把处理好的内容,发送给客户端:基础代码示例代码语言:javascriptAI代码解释/*res.send()send 方法内部会检测响应内容的类型send 方法会自动设置 http 状态码send 方法还会帮我们自动设置响应的内容类型以及编码*/// => 引入 express 框架const express = require('express')// => 创建网站服务器const app = express();app.get('/', (req, res) => {res.send('Hello Express');})app.get('/list', (req, res)=> {// => 调用express提供的res.send()方法,向客户端响应一个JSON对象 res.send({name: 'zhangsan', age: 20});})app.post('/list',(req,res) => {// => 调用express提供的res.send()方法,向客户端响应一个文本字符串})// => 监听端口app.listen(3000);console.log('网站服务器启动成功');Express之获取URL中的参数获取 URL 中携带的查询参数代码语言:javascriptAI代码解释// => 引入 express 框架const express = require('express')// => 创建网站服务器const app = express();app.get('/', (req, res) => {// => 通过 req.query 可以获取到客户端发送过来的查询参数 // => 注意:默认情况下,req.query是一个空对象 console.log(req.query) res.send(req.query)})// 监听端口app.listen(3000);console.log('网站服务器启动成功');如上,我们服务器站点已经打开为 http://localhost:3000,处理的是地址为’/'的get请求现在我们使用postman工具模拟客户端来发起get请求,并带query参数我们可以看到在模拟客户端的工具内确实是响应了JSON对象(res.send(req.query))同时我们也可以看到服务端的打印情况获取 URL 中的动态参数代码语言:javascriptAI代码解释// => 引入 express 框架const express = require('express')// => 创建网站服务器const app = express();// => :id 是一个动态的参数app.get('/user/:id',(req,res) => {// => res.params 是动态匹配到的 URL 参数,默认也是一个空对象 console.log(req.params) res.send(req.params)})// 监听端口app.listen(3000);console.log('网站服务器启动成功');同样我们来看客户端和服务端的响应情况客户端服务端当然,,也是可以有多个动态参数的,如:/user/:name/:ageExpress之托管静态资源express提供了一个非常好用的函数,叫做express.static(),通过它,我们可以非常方便地创建一个静态资源服务器,例如,通过如下代码就可以将public目录下的图片、CSS文件、JavaScript 文件对外开放访问了:代码语言:javascriptAI代码解释app.use(express.static('public'))现在,你就可以访问public目录中的所有文件了:http://localhost:3000/images/bg.jpghttp://localhost:3000/css/style.csshttp://localhost:3000/js/login.js注意:Express在指定的静态目录中查找文件,并对外提供资源的访问路径。因此,存放静态文件的目录名不会出现在URL中,就比如寻找静态资源时,就没有带上public文件目录名。代码示例代码语言:javascriptAI代码解释const express = require('express')const app = express()// => 在这里,调用 express.static() 方法,快速地对外提供静态资源app.use(express.static('./public'))app.listen(8080,() => {console.log('express server runing at http://locallhost:8080')})托管多个静态资源目录访问静态资源文件时,express.static()函数会根据目录的添加顺序查找所需的文件。如上,在访问静态资源时,比如要找的时index.html,此时,public和files中都有index.html文件夹,这样在public中找到后,便不会继续往下找了。挂载路径前缀如果希望在托管的静态资源访问路径之前,挂载路径前缀,则可以使用如下的方式:代码语言:javascriptAI代码解释app.use("/public", express.static("public"))现在,就可以通过带有/public前缀地址来访问public目录中的文件了:http://localhost3000/public/images/kitten.jpghttp://localhost:300d7public/css/style.csshttp://localhost:3000/publicljs/app.jsExpress之路由现实生活的路由在这里,路由是按健与服务之问的映射关系Express中的路由在 Express 中,路由指的是客户端的请求与服务器处理函数之间的映射关系。Express中的路由分三部分组成,分别是请求的类型,请求的URL地址,处理函数,格式如下:代码语言:javascriptAI代码解释app.METHOD(PATH,HANDLER)Express中的路由例子代码语言:javascriptAI代码解释const express = require('express')const app = express()// => 匹配 GET 请求,且请求 URL 为 /app.get('/',function(req,res) {res.send('Hello')})// => 匹配 POST 请求,且请求 URL 为 /app.post('/',function(req,res) {res.send('Got a POST request')})理解路由的匹配过程每当一个请求到达服务器之后,需要先经过路由的匹配,只有匹配成功之后,才会调用对应的处理函数。在匹配时,会按照路由的顺序进行匹配,如果请求类型和请求的URL同时匹配成功,则 Express 会将这次请求,转交给对应的function函数进行处理。路由的使用最简单的路由用法在Express中使用路由最简单的方式,就是把路由挂载到app上,如下代码语言:javascriptAI代码解释const express = require('express ')// => 创建web服务器,命名为appconst app = express()// => 挂载路由app.get('/',(req,res) => { res.send('hell World') })// => 启动 Web 服务器app.listen(8080,()=>{console.log('启动')})路由的模块化为了方便对路由进行模块化的管理,Express 不建议将路由直接挂载到app上,而是推荐将路由抽离为单独的模块。将路由抽离为单独模块的步骤如下:① 创建路由模块对应的 .js 文件② 调用 express.Router() 函数创建路由对象③ 向路由对象上挂载具体的路由④ 使用 Module.exports 向外共享路由对象⑤ 使用 app.use() 函数注册路由模块① —> ④,如下代码语言:javascriptAI代码解释/*这是路由模块*/// => 1. 导入expressconst express = require('express')// => 2. 创建路由对象const router = express.Router()// => 3. 挂载具体路由router.get('/user/list',(req,res) => {res.send('Get user List.')})router.post('/user/add',(req,res) => {res.send('Add new user.')})// => 4. 向外导出路由对象module.exports = router⑤,如下代码语言:javascriptAI代码解释const express = require('express')const app = express()// => 导入路由模块const router = require('./08-router')// => 注册路由模块app.use(router)app.listen(8080,() => {console.log('http:127.0.0.1')})为路由模块添加前缀类似于托管静态资源时,为静态资源统一挂载访问前缀一样,路由模块添加前缀的方式也非常简单:Express之中间件生活当中的例子在处理污水的时候,一般要经过三个处理环节,从而保证处理过的废水,达到排放标准。处理污水的这三个中间处理环节,就可以叫做中间件。Expres中间件的调用流程当一个请求到达 Express 的服务器之后,可以连续调用多个中间件,从而对这次请求进行预处理。Express 中间件的格式注意:中间件函数的形参列表中,必须包含 next 参数,而路由处理函数中只包含 req 和 res。因此区分是中间件处理函数还是路由处理函数的区别就是看参数列表是否包含next参数。next 函数的作用next函数是实现多个中间件连续调用的关键。它表示把流转关系转交给下一个中间件或路由。定义中间件函数可以通过如下的方式,定义一个最简单的中间件函数:代码语言:javascriptAI代码解释const express = require('express')const app = express()// => 定义一个最简单的中间件函数const mw = function(req,res,next) {console.log('这是最简单的中间件函数') // => 把流转关系,转交给下一个中间件或路由 next()}app.listen(8080,() => {console.log('Web服务启动');})全局生效的中间件客户端发起的任何请求,到达服务器之后,都会触发的中间件,叫做全局生效的中间件。通过调用app.use(中间件函数),即可定义一个全局生效的中间件,示例代码如下:代码语言:javascriptAI代码解释const express = require('express')const app = express()// => 定义一个最简单的中间件函数const mw = function(req,res,next) {console.log('这是最简单的中间件函数') // => 把流转关系,转交给下一个中间件或路由 next()}// => 全局生效的中间件app.use(mw)app.get('/',(req,res) => {console.log('这次流转到我 / 这里了') res.send('Home page')})app.get('/user',(req,res) => {res.send('User page.')})app.listen(8080,() => {console.log('Web服务启动');})接着我们使用 postman 给我们这个开启的 Web 服务器发起请求客户端:服务器:定义中间件的简化形式中间件在实际开发中的作用多个中间件之间,共享同一份req和res。基于这样的特性,我们可以在上游的中间件中,统一为req或res对象添加自定义的属性或方法,供下游的中间件或路由进行使用。代码示例代码语言:javascriptAI代码解释/*捕获请求到达到达服务器的时间*/const express = require('express')const app = express()app.use((req,res,next) => {// => 获取请求到达服务器的时间 const time = Date.now() // => 为 req 对象,挂载自定义属性,从而把时间共享给后面的所有路由 req.startTime = time next()})app.get('/',(req,res) => {console.log('这次流转到我 / 这里了' + ' 请求时间是' + req.startTime) res.send('Home page')})app.get('/user',(req,res) => {console.log('这次流转到我 /user 这里了' + ' 请求时间是' + req.startTime) res.send('User page.')})app.listen(8080,() => {console.log('Web服务启动');})定义多个全局中间件可以使用app.use()连续定义多个全局中间件。客户端请求到达服务器之后,会按照中间件定义的先后顺序依次进行调用,示例代码如下:代码语言:javascriptAI代码解释const express = require('express')const app = express()// => 定义一个全局中间件app.use((req,res,next) => {console.log('调用了第1个全局中间件') next()})// => 定义第二个全局中间件app.use((req,res,next) => {console.log('调用了第二个全局中间件') next()})// => 定义一个路由app.get('/user',(req,res) => {res.send('User page')})app.listen(8080,() => {console.log('启动')})局部生效的中间件不使用app.use0定义的中间件,叫做局部生效的中间件,示例代码如下:代码语言:javascriptAI代码解释const express = require('express')const app = express()// 1. 定义中间件函数const mw1 = (req,res,next) => {console.log('调用了局部生效的中间件') next()}// 2. 创建路由// mw1 就是局部的中间件了app.get('/',mw1,(req,res) => {res.send('Home page')})app.get('/user',(req,res) => {res.send('User page')})// => 指定端口号,并启动web服务器app.listen(8080,function(){console.log('启动');})定义多个局部中间件代码语言:javascriptAI代码解释const express = require('express')const app = express()// 1. 定义中间件函数const mw1 = (req,res,next) => {console.log('调用了第一个局部生效的中间件') next()}const mw2 = (req,res,next) => {console.log('调用了第二个局部生效的中间件') next()}// 2. 创建路由app.get('/',mw1,mw2,(req,res) => {res.send('Home page')})app.get('/user',(req,res) => {res.send('User page')})// => 指定端口号,并启动web服务器app.listen(8080,function(){console.log('启动');})中间件的注意事项一定要在路由之前注册中间件客户端发送过来的请求,可以连续调用多个中间件进行处理执行完中间件的业务代码之后,不要忘记调用next()函数为了防止代码逻辑混乱,调用next()函数后不要再写额外的代码连续调用多个中间件时,多个中间件之间,共享req和res 对象监听 req 的 data 事件在中间件中,需要监听req对象的data事件,来获取客户端发送到服务器的数据。如果数据量比较大,无法一次性发送完毕,则客户端会把数据切割后,分批发送到服务器。所以data事件可能会触发多次,每一次触发data事件时,获取到数据只是完整数据的一部分,需要手动对接收到的数据进行拼接。代码语言:javascriptAI代码解释// 定义变量,用来储存客户端发送过来的请求体数据let str = ''// 监听 req 对象的 data 事件(客户端发送过来的新的请求体数据)req.on('data',(chunk) => { // 拼接请求体数据,隐式转换为字符串 str += chunk})监听 req 的 end 事件当请求体数据接收完毕之后,会自动触发req的end 事件。因此,我们可以在req的end 事件中,拿到并处理完整的请求体数据。示例代码如下:代码语言:javascriptAI代码解释// 监听 req 对象的 end 事件(请求体发送完毕后自动触发)req.on('end',() => { // => 打印完整的请求体数据 console.log(str) // TODO: 业务逻辑 // .......})Express中间件的分类为了方便理解和记忆中间件的使用,Express 官方把常见的中间件用法,分成了5大类,分别是:应用级别的中间件通过app.use()或app.get()或 app.post(),绑定到app实例上的中间件,叫做应用级别的中间件,代码示例如下:路由级别的中间件绑定到express.Router()实例上的中间件,叫做路由级别的中间件。它的用法和应用级别中间件没有任何区别。只不过,应用级别中间件是绑定到 app实例上,路由级别中绚件摸定到router 实例上,代码示例如下:错误极别的中间件错误级别中间件的作用:专门用来捕获整个项目中发生的异常错误,从而防止项目异常崩溃的问题。格式:错误级别的中间件的 function 处理函数中,必须有 4 个形参,形参顺序从前到后,分别是(err,req,res,next)。代码示例注意:错误级别的中间件必须注册在所有路由之后。代码语言:javascriptAI代码解释// 引入 express 框架const express = require('express')// 创建网站服务器const app = express();// 1. 定义路由app.get('/',(req,res) => { // 1.1 人为的制造错误 throw new Error('服务器内部发生错误')})// 2. 定义错误级别的中间件,捕获整个项目的异常错误,从而防止程序的崩溃app.use((err,req,res,next) => {console.log('发生了错误!' + err.message) res.send('Error:' + err.message)}) // 监听端口app.listen(8080,function() {console.log('Express server is running')})Express内置的中间件自Express 4.16.0版本开始,Express 内置了3个常用的中间件,极大的提高了Express 项目的开发效率和体验:express.static快速托管静态资源的内置中间件,例如:HTML文件、图片、CSS样式等(无兼容性)express.json解析JSON格式的请求体数据(有兼容性,仅在4.16.0+版本中可用)代码语言:javascriptAI代码解释// => 配置解析 application / json 格式数据的内置中间件app.use(express.json())express.urlencoded解析URL-encoded格式的请求体数据(有兼容性,仅在4.16.0+版本中可用)代码语言:javascriptAI代码解释// => 配置解析 application / x-www-from-urlencoded 格式数据的内置中间件app.use(express.urlencoded({ extended: false }))代码示例代码语言:javascriptAI代码解释// 引入 express 框架const express = require('express')// 创建网站服务器const app = express();// 注意:除了错误级别的中间件,其他中间件,必须在路由之前进行配置// 通过 express.json 这个内置中间件,解析表单中 json 格式的数据app.use(express.json())// 通过 express.ulencoded() 这个中间件,解析表单中 url-encoded 格式的数据app.use(express.urlencoded({ extended: false }))app.post('/user',(req,res) => {// 在服务器,可以使用req.body这个属性,来接受客户端发送过来的请求体数据 // 默认情况下,如果不配置解析表单数据的中间件,则 req.body 默认等于 undefined console.log(req.body) res.send('ok')})app.post('/book',(req,res) => {console.log(req.body) res.send('ok')})app.listen(3000,function() {console.log('网站服务器启动成功');})第三方的中间件非Express官方内置的,而是由第三方开发出来的中间件,叫做第三方中间件。在项目中,大家可以按需下载并配置第三方中间件,从而提高项目的开发效率。例如:在express@4.16.0之前的版本中,经常使用body-parser这个第三方中间件,来解析请求体数据。使用步骤如下:运行npm install body-parser安装中间件使用require导入中间件调用app.use()注册并使用中间件自定义中间件需求描述与实现步骤自己手动模拟一个类似于express.urlencoded这样的中间件,来解析POST提交到服务器的表单数据。实现步骤定义中间件监听req的data事件监听req的end 事件使用querystring模块解析请求体数据将解析出来的数据对象挂载为req.body将自定义中间件封装为模块代码示例代码语言:javascriptAI代码解释// => 引入 express 框架const express = require('express')// => 创建网站服务器const app = express()// 1. 导入自己封装的中间件模块const custonBodyParser = require('./21-封装')// 2. 将自定义的中间件函数注册为全局可用的中间件app.use(custonBodyParser)app.post('/user',(req,res) => {res.send('ok') res.send(req.body)})// => 监听端口app.listen(3000,function() {console.log('网站服务器启动成功')})封装的模块代码语言:javascriptAI代码解释// => 导入 Node.js内置的 querystring 模板const bodyParser = require('body-parser')const qs = require('querystring')app.use((req,res,next) => {// => 定义中间件具体的业务逻辑 let str = '' req.on('data',(chunk) => { str += chunk }) req.on('end',() => { console.log(str) // => 在 str 中存放的是完整的请求体数据 // => 业务:把字符串格式的请求体数据,解析成对象格式 const body = qs.parse(str) console.log(body) req.body = body next() })})modules.exports = bodyParser使用Express编写接口编写 GET 接口核心代码代码语言:javascriptAI代码解释apiRouter.get('/get',(req,res) => {// 1. 获取到客户端通过查询字符串,发送到服务器的数据 const query = req.query // 2. 调用 res.send() 方法,把数据响应给客户端 res.send({ status: 0, // 状态,0 表示成功 msg: 'GET请求成功!', // 状态描述 data: query // 需要响应给客户端的具体数据 })})编写 POST 接口核心代码代码语言:javascriptAI代码解释apiRouter.post('/post',(req,res) => {// 1. 获取客户端通过请求体,发送到服务器的 URL-encoded 数据 const body = req.body // 2. 调用 res.send() 方法,把数据响应给客户端 res.send({ status: 0, // 状态,0 表示成功,1 表示失败 msg: 'POST请求成功!', // 状态描述信息 data: body // 需要响应给客户端的具体数据 })})注意:如果要获取URL-encoded格式的请求体数据,必须配置中间件 app.use(express.urlencoded(extended:false))创建服务器及编写简单接口首先创建基本的服务器,提供接口的导入口代码语言:javascriptAI代码解释const express = require('express') // => 导入 expressconst app = express() // => 创建服务器实例app.use(express.urlencoded({extended:false})) // => 配置解析表单的数据中间件// => 本来路由写在这里的,现在模块化管理了,导入注册即可// => 导入并注册路由模块,这样客户端到达的请求就会到对应封装好的接口中去匹配对应的路由const router = require('./23-接口')app.use('/api',router)// => 启动服务器app.listen(3000,() => {console.log('Web服务器已经创建');})封装API接口并暴露链接代码语言:javascriptAI代码解释const express = require('express')const router = express.Router()// => 在这里挂载对应的路由// 如下, 编写一个 GET 接口router.get('/get',(req,res) => {// 通过req.query获取客户端通过查询字符串,发送到服务器的数据 const query = req.query // 调用res.send()方法,向客户端响应处理的结果 res.send({ status:0, // => 0表示处理成功,1表示处理失败 msg:'GET 请求成功', // => 状态的描述 data: query // => 需要响应给客户端的数据 })})// 如下,编写一个 POST 接口router.post('/post',(req,res) => {// 通过 req.body 获取请求体中包含的 url-encoded 格式的数据 const body = req.body // 调用 res.send 方法,向客户端响应数据 res.send({ status:0, msg:'POST请求成功', data: body })})module.exports = router使用Express框架链接sQlite3数据库一. 安装sqlite3,运行如下命令代码语言:javascriptAI代码解释yarn add sqlite3 --ignore-scripts二. 实现链接文件夹目录代码语言:javascriptAI代码解释▽ Message ▸ node_modules ▸ public ▸ hello.html▸ db ▸ db.sqlite3 ▸ dbutils.js▸ router ▸ MessageRouter.js▸ app.js ▸ package-lock.json ▸ package.json ▸ yarn.lock1、创建数据库创建数据库文件:注意 ③,数据文件配置的路径是要和我们项目调用数据文件保持一致新建一个表:添加字段:添加数据2、使用NODE开始链接数据库首先,我们希望的是,使用我们搭建的服务器来连接数据库,那么创建服务器app.js代码语言:javascriptAI代码解释const express = require("express")const path = require("path")const app = express()let port = 3000// => 为前端开放跨域请求app.use(function (req,res,next) {// => 设置允许跨域的域名,* 代表允许任意域名跨域 res.header("Access-Control-Allow-Origin","*"); // => 允许的header类型 res.header("Access-Control-Allow-Headers","content-type"); // => 跨域允许的请求方式 res.header("Access-Control-Allow-Methods","DELETE,PUT,POST,GET,OPTIONS"); if(req.method == "OPTIONS") res.sendStatus(200) // => 让options尝试请求快速结束 else next()})// => 导入路由app.use("/message",require("./router/MessageRouter.js"))// => 导入静态资源app.use(express.static(path.join(__dirname,"./public")))app.get("/",(req,res) => {res.send("hello")})app.listen(port,(req,res) => {console.log(`启动成功`)})然后我们配置相关路由router / MessageRouter.js代码语言:javascriptAI代码解释const express = require("express")const {db} = require("../db/dbutils")var router = express.Router()router.get("/test",(req,res) => {// => 查询数据库 db.all("select * from `message`",(err,rows) => { res.send(rows) })})module.exports = router为了使得数据库导出及复用性更高,我们将其单独封装成一个链接db / dbutils.js代码语言:javascriptAI代码解释const path = require("path") // => 导入 path 模块const sqlite3 = require("sqlite3").verbose() // => 导入依赖const db = new sqlite3.Database(path.join(__dirname,"./db.sqlite3")) // => 实例化// => 暴露module.exports = {db}启动查看是否链接成功接口的跨域问题咱们刚才编写的 GET 和 POST 接口,存在一个很严重的问题,不支持跨域请求(跨域:指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器对javascript施加的安全限制)。我们仍然使用刚才所打开的服务器,现在测试发起请求代码语言:javascriptAI代码解释<!DOCTYPE html><meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <script src="https://cdn.staticfile.org/jquery/3.7.0/jquery.slim.js"></script><button id="btnGET">GET</button> <button id="btnPOST">POST</button> <script> // => 1. 测试GET接口 $('#btnGET').on('click',function() { $.ajax({ type: 'GET', url: 'http://localhost:3000/api/get', data: {name:'hv',age:20}, success: function(res) { console.log(res) } }) }) // => 2. 测试POST接口 $('#btnPOST').on('click',function() { $.ajax({ type: 'POST', url: 'http://localhost:3000/api/get', data: {bookname:'水浒传',author:'施耐庵'}, success: function(res) { console.log(res) } }) }) </script>如下,可以看见违反了同源策略( 同源策略:是指协议,域名,端口都要相同,其中有一个不同都会产生跨域)。如下的协议名是 file以前我们使用 postman 发起请求的时候,是没有违反同源策略的,用的就是服务器的域名。使用 cors 中间件解决跨域问题(主流的解决方案,推荐使用)cors 是 Express的一个第三方中间件。通过安装和配置cors中间件,可以很方便地解决跨域问题。使用步骤分为如下3步:运行 npm install cors 安装中间件使用 const cors = require('cors') 导入中间件在路由之前 调用app.use(cors()) 配置中间件代码语言:javascriptAI代码解释const express = require('express') // => 导入 expressconst app = express() // => 创建服务器实例app.use(express.urlencoded({extended:false})) // => 配置解析表单的数据中间件// => 一定要在路由之前,配置 cors 这个中间件,从而解决接口跨域的问题const cors = require('cors')app.use(cors())// => 本来路由写在这里的,现在模块化管理了,导入注册即可// => 导入并注册路由模块,这样客户端到达的请求就会到对应封装好的接口中去匹配对应的路由const router = require('./23-接口')app.use('/api',router)// => 启动服务器app.listen(3000,() => {console.log('Web服务器已经创建');})注意:CORS主要在服务器端进行配置。客户端浏览器无须做任何额外的配置,即可请求开启了CORS的接口。CORS在浏览器中有兼容性。只有支持XMLHttpRequest Level2的浏览器,才能正常访问开启了CORS的服务端接口。结语 保持热爱,永远都在前进的路上❤️
-
LLM 1.前置知识 微调的模型集中在以下模型:DeepSeek、GLM、Llama、Qwen,其中在初步微调中,DeepSeek和Qwen表现较好,于是选择加入DeepSeek和Qwen较大参数量的模型进行微调测试 2.在微调过程中,主要关注以下因素的调整对模型表现的影响,包括但不限于:训练集数据量、训练集不同类型数据的配比、训练集单条数据长度、cutoff_len(截断长度)、Qlora、lora_dropout(丢弃部分神经元防止过拟合)、learning_rate(学习率)、Epochs(训练轮次)、模型参数规模等3.训练可用GPU:A800,微调方法:lora,集成平台:llama-factory2.微调平台使用 部署llama-factory,详见:https://llamafactory.readthedocs.io/en/latest/getting_started/installation.html 部署完成之后熟悉各项微调参数: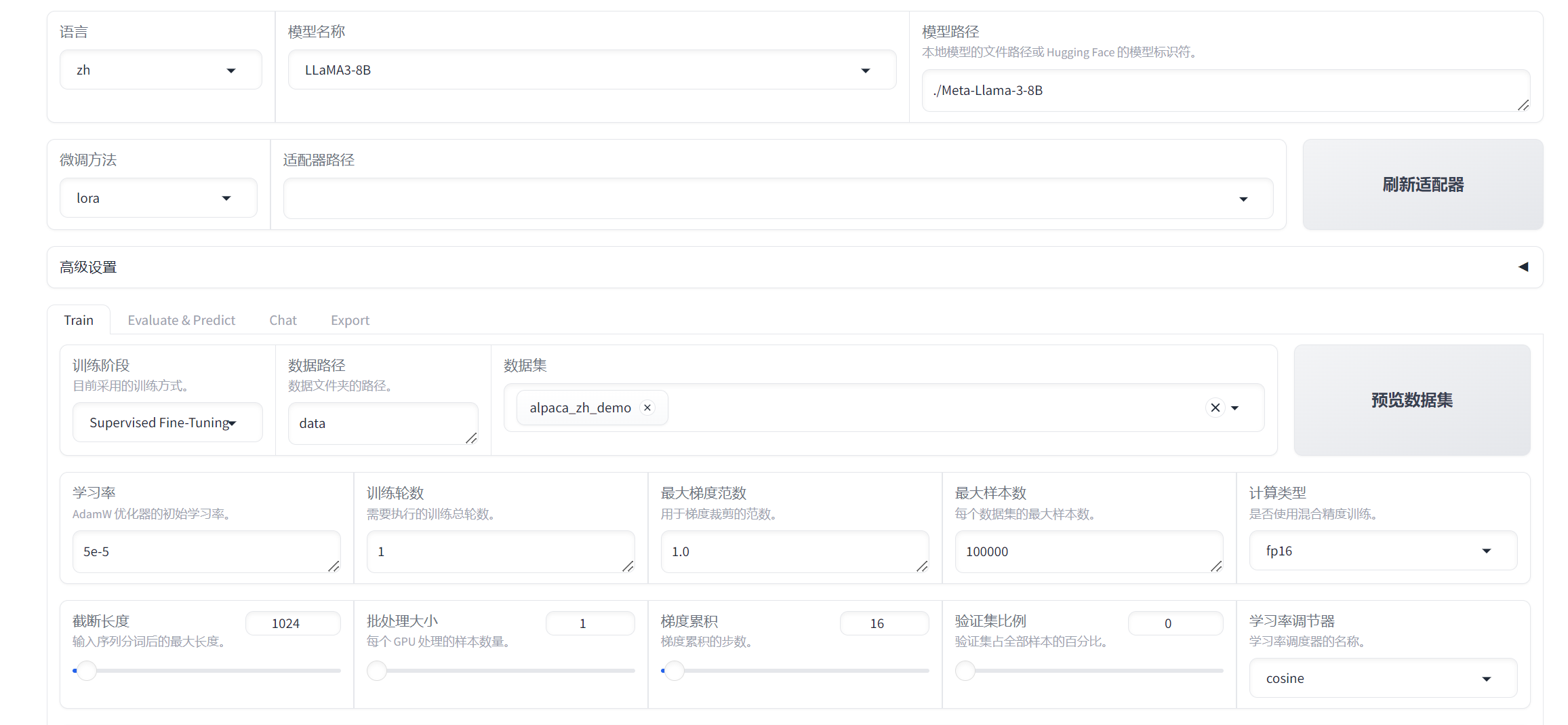 3.以微调材料大模型的经验,以下微调参数比较重要:训练集数据量、训练集不同类型数据的配比、训练集单条数据长度、cutoff_len(截断长度)、Qlora(参数精度:16、8、4)、lora_dropout(丢弃部分神经元防止过拟合)、learning_rate(学习率)、Epochs(训练轮次)、模型参数规模注意:(1)部分微调参数调整需要补充环境,比如qlora(2)模型参数规模受限于gpu,要选择合适的模型和相应的参数规模(3)可以在微调前后使用llama-factory的评估来测试模型在测试集上各个指标的提升,所以在准备数据集的时候既需要准备训练集也需要测试集
-
网站搭建流程相关内容 内网穿透frp c端控制{dotted startColor="#ff6c6c" endColor="#1989fa"/}以下环境为ubuntu 20.04c端即为client 为用户端 为本地主机所用 信息会被s端 即server端接受首先要下载开源软件frp资源包 frp有官网资源 按照你的系统来下载就可以windows的可能会爆毒 属于正常 关闭杀毒软件即可c端一般配置如下# --- 核心连接层 --- # 锁定你的公网 IP 这里随便写了 通信端口你随意 serverPort为frp通信用 serverAddr = "8.8.8.8" serverPort = 7000 # 身份验证 auth.method = "token" auth.token = "此处和server端一致 设你想要的密钥" # --- 流量路由层 --- # 【通道一】主网站流量:将云端的 epoch42.cn 流量,收敛到本地的端口 # 这个位置的流量我在云端用nginx进行路由识别具体的域名 [[proxies]] name = "epoch42-web" type = "http" localPort = 80XX customDomains = ["epoch42.cn", "www.epoch42.cn"]frpc的安装位置任意 你记得就好 里面会有相应的配置文件 最新的配置文件会是驼峰命名法可以编写系统文件将frpc注册到系统 或者直接启动frpc也行sudo nano /etc/systemd/system/frpc.service替换以下的xxxx 换成你的信息 云端保持一致即可[Unit] Description=Frp Client Service After=network.target [Service] Type=simple User=xxxxx WorkingDirectory=/xxxx/frp ExecStart=/xxxxx/frp/frpc -c /xxxxx/frp/frpc.toml Restart=on-failure RestartSec=5s [Install] WantedBy=multi-user.target然后经典三步就可以了 这样比较省心 直接后台挂着了sudo systemctl daemon-reload sudo systemctl enable frpc sudo systemctl start frpc常用后台控制命令先安装一些必备软件包sudo apt install nodejs npm -y # 全局安装 pm2 http-server sudo npm install -g pm2 sudo npm install -g http-server # 常用 pm2 命令 # 启动应用 pm2 start app.js # 查看所有运行的应用 pm2 list # 查看日志 pm2 logs # 停止应用 pm2 stop app_name # 重启应用 pm2 restart app_name # 删除应用 pm2 delete app_name # 设置开机自启 pm2 startup pm2 save # 常用http-server命令 # 在当前目录启动静态服务器(默认端口 8080) http-server # 指定端口 http-server -p 3000 # 指定目录 http-server /path/to/directory -p 8080 # 启用 CORS http-server --cors # 静默模式(不输出日志) http-server -s使用 pm2 管理 http-server# 启动 http-server 并由 pm2 管理 pm2 start http-server --name "static-server" -- -p 8080 # 或者指定目录 pm2 start http-server --name "my-site" -- -p 3000 /home/niu/www
-
-
本网站搭建 😁 太难啦 😁 最开始打算本地mysql+ghost/or各种博客框架+nginx 本地环境是多用户ubuntu服务器 端口环境异常恶劣hh nginx启动很困难 网络环境为内网环境 为了实现网站梦 遂开始从0构建 基本路线是本地frpc——阿里云ecs的frps+nginx上面 域名解析到ecs的公网ip上面 一切的原因都是因为太对了出此下策 (气笑了) ::(乖) 现在就是简单的使用pm2托管了typecho架构的网站 使用sqlite 使用了一些大佬的开源主题+插件这里给下他们的链接苏晓晴 Joe little-gt why not nginx? 😊 openresty LISTEN 80 因为环境下太多用户 改用openresty也很困难 配置文件如果在root下直接启动过于危险 so passwhy not mysql? 😆 有服务跑在了3306 而大部分默认配置都直接要跑3306 一旦要修改端口不知道要改多少内容 而本人是mysql菜鸡 所以选择了最简单的方式(已被mysql权限狠狠折磨了)why not ...? 😭 最开始把框架想的很大 最后发现自己不行 甚至尝试自己写前后端+数据库架构搭建 也能搭出来 但是你懂的 异常简陋 所以砍掉成现在这个样子了我深深感受到了什么叫做 如无必要勿增实体typecho:轻量级博客框架——>基于php下载:从 typecho 官网 下载压缩包。解压:放到你想要启动网站的目录下(可以新建一个文件夹比如 typecho_site)(文件夹名字随便你)。安装:访问域名,填入站点信息,30秒就能装好。cd /跳转到你放typecho的文件夹 # 启动 PHP 内置服务器 # -S 指定监听地址和端口 # -t 指定网站根目录php -S 0.0.0.0:8888 -t /你放typecho的根目录文件夹 (8888改成你喜欢的端口就行了)php不是后台托管命令 我习惯用pm2了 比较方便管理pm2 start "php -S 0.0.0.0:8888 -t /你放typecho的根目录文件夹" --name "typecho-blog" 上述命令其实就是让系统找到pm2这个服务/软件 start:启动 双引号里为具体命令 --name:自定义一下改进程名字查看状态:pm2 list(你会看到 typecho-blog 在列表中显示 online)。 如下│ id │ name │ mode │ ↺ │ status │ cpu │ memory │├────┼────────────────────┼──────────┼──────┼───────────┼──────────┼──────────┤│ 7 │ epoch42_blog │ fork │ 0 │ online │ 0% │ 76.0mb │你可以使用 pm2 restart epoch42_blog 或者 pm2 restart 7 (7是服务的id) 来重启typecho (如果你对typecho系统文件进行更改了的话)映射经过上述命令 你其实已经完成一大半了 typecho会显示在你本地服务器端口8888上面(你命令中的端口)如果你是直接在公网ecs上面使用 那么你只需要把端口绑到你的域名就好了当然 如何申请域名并拥有一个属于自己的域名(在国内)也是很麻烦主题/插件 typecho默认的主题和后台内容并不友好 我也在探索阶段 我在前面提到的开源大佬中 分别有后台和主题的代码 可以很快弄出一个像我这样的网站(你也试试吧xd 只需要把他们的压缩文件夹解压并且放到typecho的相应目录下即可 /usr/plugins (插件 /usr/themes (主题